VTA 入门
单击 此处 下载完整的示例代码
本文介绍如何用 TVM 对 VTA 设计进行编程。
本教程演示在 VTA 设计的向量 ALU 上,实现向量加法的基本 TVM 工作流程。此过程包括,将计算降级到底层加速器操作所需的特定 schedule 转换。
首先导入 TVM(深度学习优化编译器)。进行 VTA 设计,还需要导入 VTA Python 包,这个包里包含针对 TVM 的 VTA 特定扩展。
from __future__ import absolute_import, print_function
import os
import tvm
from tvm import te
import vta
import numpy as np
加载 VTA 参数
VTA 的设计遵循模块化和可定制的原则。因此,用户可以自由修改影响硬件设计布局的高级硬件参数。这些参数在 vta_config.json 文件中由它们的 log2 值指定。这些 VTA 参数可以通过 vta.get_env 函数加载。
最后,在 vta_config.json 文件中指定 TVM target。当设置为 sim 时,会在行为 VTA 模拟器内执行。若要在 Pynq FPGA 开发平台上运行本教程,请遵循 VTA 基于 Pynq 的测试设置指南。
env = vta.get_env()
FPGA 编程
以 Pynq FPGA 开发板为 target 时,要为开发板配置 VTA 比特流。
# 要 TVM RPC 模块和 VTA 模拟器模块
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
# 从 OS 环境中读取 Pynq RPC 主机 IP 地址和端口号
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# 在 Pynq 上配置比特流和 runtime 系统
# 匹配 vta_config.json 文件指定的 VTA 配置。
if env.TARGET == "pynq" or env.TARGET == "de10nano":
# 确保 TVM 是使用 RPC=1 编译的
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# 重新配置 JIT runtime
vta.reconfig_runtime(remote)
# 使用预编译的 VTA 比特流对 FPGA 进行编程。
# 可以通过传递比特流文件的路径而非 None,
# 使用自定义比特流对 FPGA 进行编程
vta.program_fpga(remote, bitstream=None)
# 在模拟模式下,本地托管 RPC 服务器。
elif env.TARGET in ("sim", "tsim", "intelfocl"):
remote = rpc.LocalSession()
if env.TARGET in ["intelfocl"]:
# 对 intelfocl aocx 编程
vta.program_fpga(remote, bitstream="vta.bitstream")
计算声明
第一步,描述计算。 TVM 采用张量语义,每个中间结果表示为多维数组。用户需要描述生成输出张量的计算规则。
此示例描述了一个向量加法,分为多个计算阶段,如下面的数据流图所示。首先,描述主存储器中的输入张量 A 和 B。然后,声明 VTA 芯片缓冲区里的中间张量 A_buf 和 B_buf。这个额外的计算阶段使得可以显式地暂存缓存的读和写。第三,描述将 A_buf 添加到 B_buf,产生 C_buf 的向量加法计算。最后一个操作是,强制转换并复制回 DRAM,产生结果张量 C。
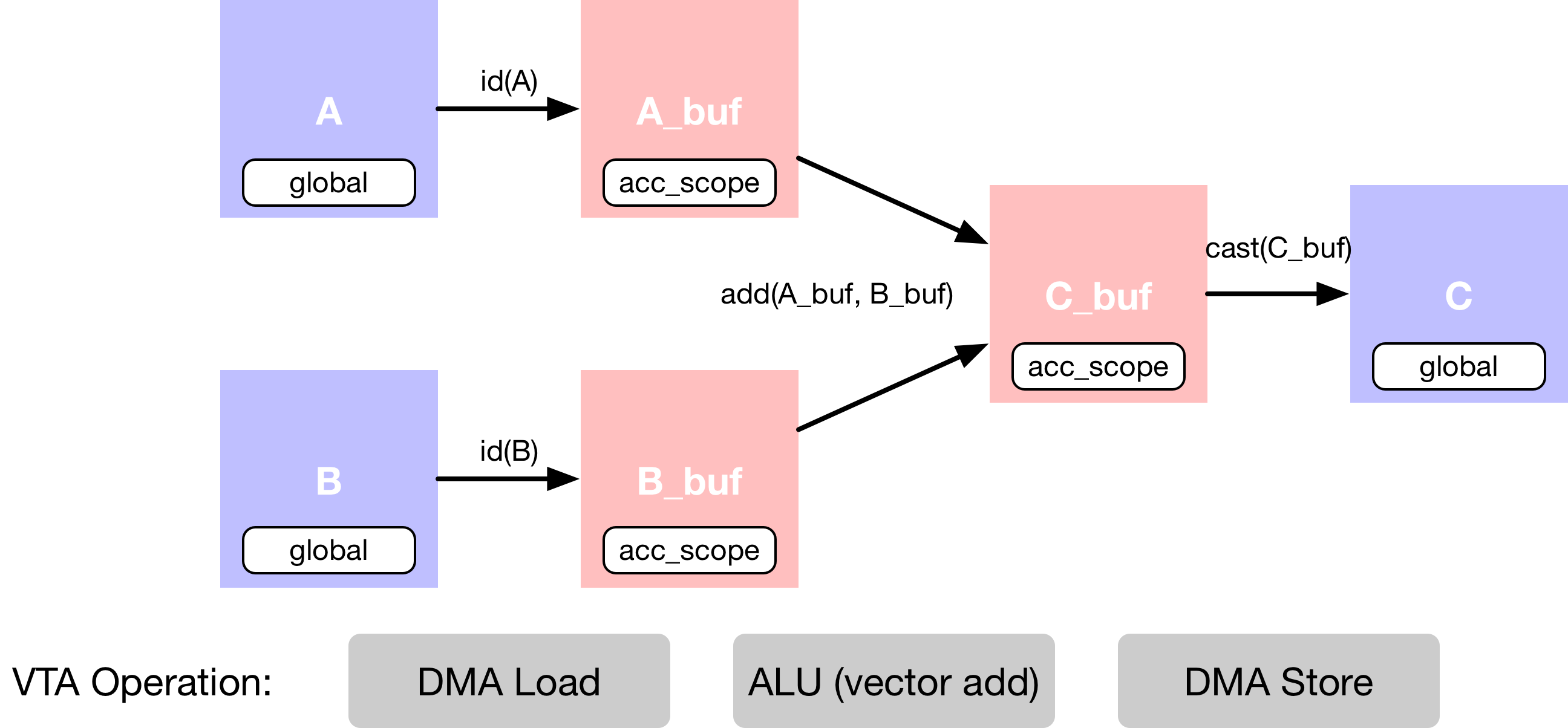
输入占位符
以平铺数据格式描述占位符张量 A 和 B,匹配 VTA 向量 ALU 规范的数据布局要求。
对于 VTA 的通用操作(例如向量相加),图块大小为 (env.BATCH, env.BLOCK_OUT)。维度在 vta_config.json 配置文件中指定,默认设置为 (1, 16) 向量。
此外,A 和 B 的数据类型还要和 vta_config.json 文件中设置的 env.acc_dtype 匹配,即为 32 位整数。
# 输出通道因子 m - 总共 64 x 16 = 1024 输出通道
m = 64
# Batch 因子 o - 总共 1 x 1 = 1
o = 1
# A 平铺数据格式的占位符张量
A = te.placeholder((o, m, env.BATCH, env.BLOCK_OUT), name="A", dtype=env.acc_dtype)
# B 平铺数据格式的占位符张量
B = te.placeholder((o, m, env.BATCH, env.BLOCK_OUT), name="B", dtype=env.acc_dtype)
拷贝缓冲区
硬件加速器的特点之一是必须显式管理芯片存储器。这意味着要描述中间张量 A_buf 和 B_buf,它们可以具有不同于原始占位符张量 A 和 B 的内存范围。
然后在调度阶段,告诉编译器 A_buf 和 B_buf 位于 VTA 的芯片缓冲区(SRAM)中,而 A 和 B 在主存储器(DRAM)中。将 A_buf 和 B_buf 描述为计算操作(恒等函数)的结果。编译器之后可将其解释为缓存的读操作。
# A 复制缓冲区
A_buf = te.compute((o, m, env.BATCH, env.BLOCK_OUT), lambda *i: A(*i), "A_buf")
# B 复制缓冲区
B_buf = te.compute((o, m, env.BATCH, env.BLOCK_OUT), lambda *i: B(*i), "B_buf")
向量加法
接下来用另一个计算操作来描述向量加法结果张量 C。计算函数接收张量的 shape,以及描述张量每个位置计算规则的 lambda 函数。
这个阶段只声明如何计算,不会发生任何计算。
# 描述 in-VTA 向量加法
C_buf = te.compute(
(o, m, env.BATCH, env.BLOCK_OUT),
lambda *i: A_buf(*i).astype(env.acc_dtype) + B_buf(*i).astype(env.acc_dtype),
name="C_buf",
)
转换结果
计算完成后,将 VTA 计算的结果返回主存。
内存存储限制
VTA 的特点之一是它只支持窄的 env.inp_dtype 数据类型格式的 DRAM 存储。这减少了内存传输的数据占用时间(在基本矩阵乘法示例中,对此进行了更多说明)。
对窄的输入激活数据格式执行最后一个类型转换操作。
# 转换为输出类型,并发送到主存
C = te.compute(
(o, m, env.BATCH, env.BLOCK_OUT), lambda *i: C_buf(*i).astype(env.inp_dtype), name="C"
)
本教程的计算声明部分到此结束。
调度计算
虽然上面描述了计算规则,但可以通过多种方式获得 C。TVM 要求用户提供名为 schedule 的计算实现。
schedule 是对原始计算的一组转换,它在不影响正确性的情况下,转换计算的实现。这个简单的 VTA 编程教程旨在演示将原始 schedule 映射到 VTA 硬件原语的基本 schedule 转换。
默认 Schedule
构建 schedule 后,schedule 默认以下面的方式计算 C:
# 查看生成的 schedule
s = te.create_schedule(C.op)
print(tvm.lower(s, [A, B, C], simple_mode=True))
输出结果:
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(int32), int32, [1024], []),
B: Buffer(B_2: Pointer(int32), int32, [1024], []),
C: Buffer(C_2: Pointer(int8), int8, [1024], [])}
buffer_map = {A_1: A, B_1: B, C_1: C}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, int32, [1, 64, 1, 16], []), B_1: B_3: Buffer(B_2, int32, [1, 64, 1, 16], []), C_1: C_3: Buffer(C_2, int8, [1, 64, 1, 16], [])} {
allocate(A_buf: Pointer(global int32), int32, [1024]), storage_scope = global;
allocate(B_buf: Pointer(global int32), int32, [1024]), storage_scope = global {
for (i1: int32, 0, 64) {
for (i3: int32, 0, 16) {
let cse_var_1: int32 = ((i1*16) + i3)
A_buf_1: Buffer(A_buf, int32, [1024], [])[cse_var_1] = A[cse_var_1]
}
}
for (i1_1: int32, 0, 64) {
for (i3_1: int32, 0, 16) {
let cse_var_2: int32 = ((i1_1*16) + i3_1)
B_buf_1: Buffer(B_buf, int32, [1024], [])[cse_var_2] = B[cse_var_2]
}
}
for (i1_2: int32, 0, 64) {
for (i3_2: int32, 0, 16) {
let cse_var_3: int32 = ((i1_2*16) + i3_2)
A_buf_2: Buffer(A_buf, int32, [1024], [])[cse_var_3] = (A_buf_1[cse_var_3] + B_buf_1[cse_var_3])
}
}
for (i1_3: int32, 0, 64) {
for (i3_3: int32, 0, 16) {
let cse_var_4: int32 = ((i1_3*16) + i3_3)
C[cse_var_4] = cast(int8, A_buf_2[cse_var_4])
}
}
}
}
虽然这个 schedule 有意义,但它不会编译为 VTA。为了生成正确的代码,要应用调度原语和代码注释,将调度转换为可以直接降级到 VTA 硬件内联函数的调度。包括:
- DMA 复制操作,接收全局范围的张量,并将其复制到局部范围的张量中。
- 即将执行向量加法的向量 ALU 操作。
缓冲区范围
首先,设置拷贝缓冲区的范围,告诉 TVM 这些中间张量存储在 VTA 的芯片 SRAM 缓冲区中。接下来告诉 TVM,A_buf、B_buf、C_buf 在 VTA 芯片累加器缓冲区中,该缓冲区用作 VTA 的通用寄存器文件。
将中间张量的范围设置为 VTA 的芯片累加器缓冲区。
s[A_buf].set_scope(env.acc_scope)
s[B_buf].set_scope(env.acc_scope)
s[C_buf].set_scope(env.acc_scope)
输出结果:
stage(C_buf, compute(C_buf, body=[(A_buf[i0, i1, i2, i3] + B_buf[i0, i1, i2, i3])], axis=[iter_var(i0, range(min=0, ext=1)), iter_var(i1, range(min=0, ext=64)), iter_var(i2, range(min=0, ext=1)), iter_var(i3, range(min=0, ext=16))], reduce_axis=[], tag=, attrs={}))
DMA 传输
调度 DMA 传输,将 DRAM 中的数据移入和移出 VTA 芯片缓冲区。插入 dma_copy 编译指示,向编译器表明复制操作将通过 DMA 批量执行,这在硬件加速器中很常见。
# 用 DMA 编译指示标记缓冲区拷贝,将拷贝循环映射到
# DMA 传输操作
s[A_buf].pragma(s[A_buf].op.axis[0], env.dma_copy)
s[B_buf].pragma(s[B_buf].op.axis[0], env.dma_copy)
s[C].pragma(s[C].op.axis[0], env.dma_copy)
ALU 操作
VTA 有一个向量 ALU,可以对累加器缓冲区中的张量执行向量运算。若要告诉 TVM 给定操作要映射到 VTA 的向量 ALU,需要用 env.alu 编译指示来显式标记向量加法循环。
# 告诉 TVM 要在 VTA 的向量 ALU 上执行计算
s[C_buf].pragma(C_buf.op.axis[0], env.alu)
# 查看最终确定的 schedule
print(vta.lower(s, [A, B, C], simple_mode=True))
输出结果:
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(int32), int32, [1024], []),
B: Buffer(B_2: Pointer(int32), int32, [1024], []),
C: Buffer(C_2: Pointer(int8), int8, [1024], [])}
buffer_map = {A_1: A, B_1: B, C_1: C}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, int32, [1, 64, 1, 16], []), B_1: B_3: Buffer(B_2, int32, [1, 64, 1, 16], []), C_1: C_3: Buffer(C_2, int8, [1, 64, 1, 16], [])} {
attr [IterVar(vta: int32, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), A_2, 0, 64, 1, 64, 0, 0, 0, 0, 0, 3, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), B_2, 0, 64, 1, 64, 0, 0, 0, 0, 64, 3, dtype=int32)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushALUOp" {
@tir.call_extern("VTAUopLoopBegin", 64, 1, 1, 0, dtype=int32)
@tir.vta.uop_push(1, 0, 0, 64, 0, 2, 0, 0, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 3, dtype=int32)
}
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 3 {
@tir.vta.coproc_dep_pop(2, 3, dtype=int32)
@tir.call_extern("VTAStoreBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), 0, 4, C_2, 0, 64, 1, 64, dtype=int32)
}
@tir.vta.coproc_sync(, dtype=int32)
}
本教程的调度部分到此结束。
TVM 编译
指定 schedule 后,可以将其编译为 TVM 函数。TVM 默认编译为一个类型擦除的函数,可以直接从 Python 端调用。
以下代码用 tvm.build 创建一个函数。build 函数接收 schedule、所需的函数签名(包括输入和输出)以及要编译到的目标语言。
my_vadd = vta.build(
s, [A, B, C], tvm.target.Target("ext_dev", host=env.target_host), name="my_vadd"
)
输出结果:
/workspace/python/tvm/driver/build_module.py:267: UserWarning: target_host parameter is going to be deprecated. Please pass in tvm.target.Target(target, host=target_host) instead.
"target_host parameter is going to be deprecated. "
保存模块
TVM 将模块保存到文件中,方便后续加载。这称为 ahead-of-time 编译,可以节省一些编译时间。更重要的是,这使得我们可以在开发机器上交叉编译可执行文件,并通过 RPC 将其发送到 Pynq FPGA 板执行。
# 将编译后的模块写入目标文件。
temp = utils.tempdir()
my_vadd.save(temp.relpath("vadd.o"))
# 通过 RPC 发送可执行文件
remote.upload(temp.relpath("vadd.o"))
加载模块
可以从文件系统中加载编译好的模块来运行代码。
f = remote.load_module("vadd.o")
运行函数
编译好的 TVM 函数使用简洁的 C API,它可从任意语言调用。
TVM 在 Python 中提供了一个基于 DLPack 标准的数组 API,来快速测试和原型设计。
- 首先创建一个远程 context(用于在 Pynq 上远程执行)。
- 然后
tvm.nd.array相应地格式化数据。 f()运行实际计算。numpy()以可解释的格式拷贝结果数组。
# 获取远程设备 context
ctx = remote.ext_dev(0)
# 在(-128, 128] 的 int 范围内随机初始化 A 和 B 数组
A_orig = np.random.randint(-128, 128, size=(o * env.BATCH, m * env.BLOCK_OUT)).astype(A.dtype)
B_orig = np.random.randint(-128, 128, size=(o * env.BATCH, m * env.BLOCK_OUT)).astype(B.dtype)
# 将 A 和 B 数组从 2D 打包为 4D 打包布局
A_packed = A_orig.reshape(o, env.BATCH, m, env.BLOCK_OUT).transpose((0, 2, 1, 3))
B_packed = B_orig.reshape(o, env.BATCH, m, env.BLOCK_OUT).transpose((0, 2, 1, 3))
# 用 tvm.nd.array 将输入/输出数组格式化为 DLPack 标准
A_nd = tvm.nd.array(A_packed, ctx)
B_nd = tvm.nd.array(B_packed, ctx)
C_nd = tvm.nd.array(np.zeros((o, m, env.BATCH, env.BLOCK_OUT)).astype(C.dtype), ctx)
# 调用模块进行计算
f(A_nd, B_nd, C_nd)
验证正确性
用 numpy 计算推理结果,并得出结论:矩阵乘法的输出是正确的。
# 用 numpy 计算参考结果
C_ref = (A_orig.astype(env.acc_dtype) + B_orig.astype(env.acc_dtype)).astype(C.dtype)
C_ref = C_ref.reshape(o, env.BATCH, m, env.BLOCK_OUT).transpose((0, 2, 1, 3))
np.testing.assert_equal(C_ref, C_nd.numpy())
print("Successful vector add test!")
输出结果:
Successful vector add test!
总结
本教程通过一个简单的向量加法示例,展示了如何用 TVM 对深度学习加速器 VTA 进行编程。一般工作流程包括:
- 通过 RPC 用 VTA 比特流对 FPGA 进行编程。
- 通过一系列计算来描述向量加法计算。
- 描述如何用调度原语执行计算。
- 将函数编译为 VTA target。
- 运行编译好的模块,并根据 numpy 实现进行验证。
欢迎查看其他示例和教程,了解有关 TVM 支持的操作、调度原语和其他功能的更多信息,从而对 VTA 进行编程。