简单矩阵乘法
单击 此处 下载完整的示例代码
本教程以 VTA 入门 教程为基础,并介绍用 TVM workflow 在 VTA 上实现矩阵乘法所需的其他概念。
RPC 设置
首先对 Pynq 的 FPGA 进行编程,并构建其 RPC runtime,步骤与 VTA 入门教程类似。
from __future__ import absolute_import, print_function
import os
import tvm
from tvm import te
import vta
import numpy as np
from tvm import rpc
from tvm.contrib import utils
from vta.testing import simulator
# 从 3rdparty/vta-hw/config/vta_config.json 文件加载 VTA 参数
env = vta.get_env()
# 从 OS 环境中读取 Pynq RPC 主机 IP 地址和端口号
host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
port = int(os.environ.get("VTA_RPC_PORT", "9091"))
# 在 Pynq 上配置比特流和 runtime 系统
# 匹配 vta_config.json 文件指定的 VTA 配置。
if env.TARGET == "pynq" or env.TARGET == "de10nano":
# 确保 TVM 是使用 RPC=1 编译的
assert tvm.runtime.enabled("rpc")
remote = rpc.connect(host, port)
# 重新配置 JIT runtime
vta.reconfig_runtime(remote)
# 使用预编译的 VTA 比特流对 FPGA 进行编程。
# 可以通过传递比特流文件的路径
# 使用自定义比特流而非 None对 FPGA 进行编程。
vta.program_fpga(remote, bitstream=None)
# 在模拟模式下,本地托管 RPC 服务器。
elif env.TARGET in ["sim", "tsim"]:
remote = rpc.LocalSession()
计算声明
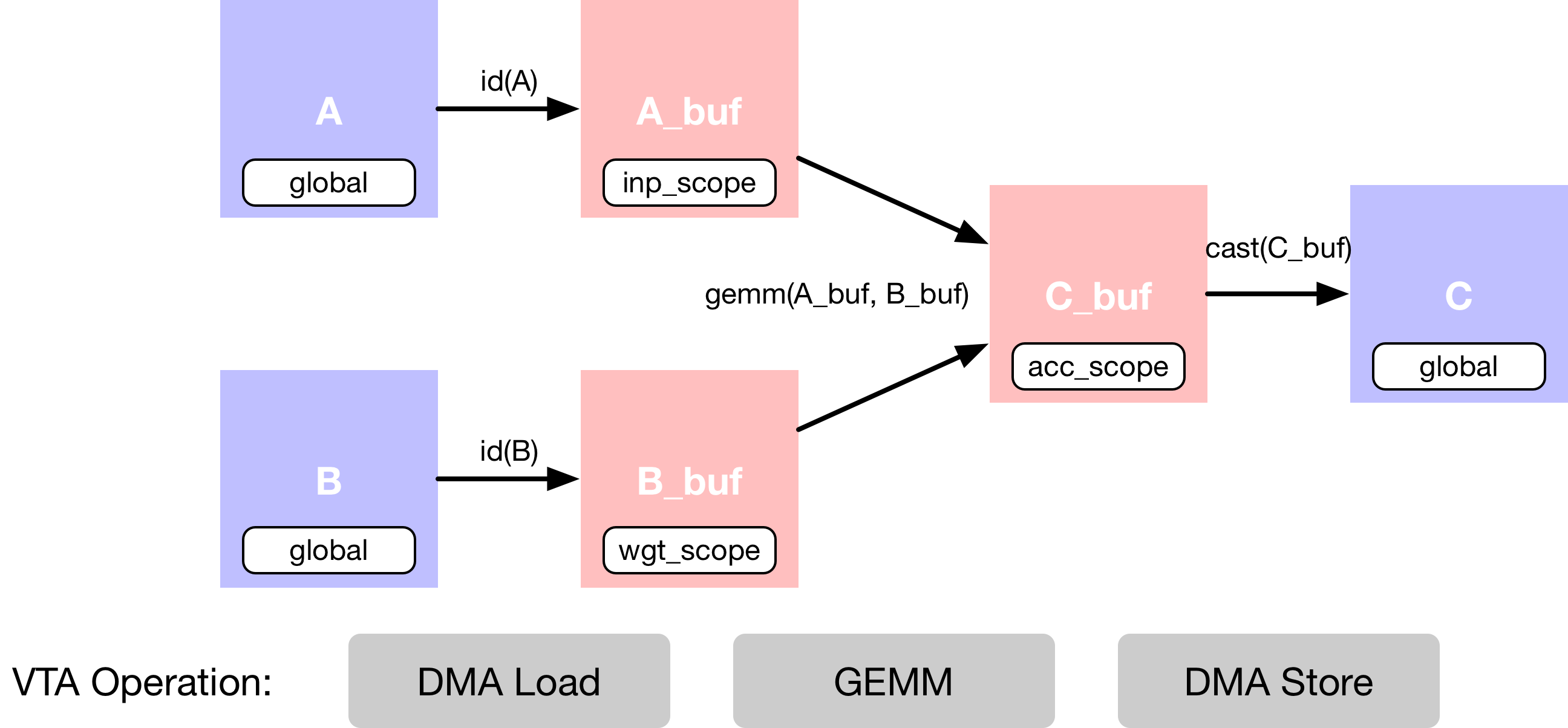
示例中描述了一个简单的矩阵乘法加法,它需要多个计算阶段,如下面的数据流图所示。首先,描述主存储器中的输入张量 A 和 B。然后,声明 VTA 的芯片上缓冲区的中间张量 A_buf 和 B_buf。这个额外的计算阶段使得能够显式地暂存缓存的读和写。第三,描述对 A_buf 和 B_buf 的矩阵乘法计算,产生乘积矩阵 C_buf。最后一个操作是,强制转换并拷贝回 DRAM,进入结果张量 C。
数据布局
以平铺数据格式描述占位符张量 A 和 B,匹配 VTA 张量 core 提出的数据布局要求。
数据平铺
目标加速器之所以复杂,一个很重要的原因就是需要确保数据布局与加速器设计要求的布局相匹配。VTA 的设计以张量 core为核心,它在激活矩阵和权重矩阵之间每个周期执行一次矩阵-矩阵运算,将结果矩阵添加到累加器矩阵,如下图所示。
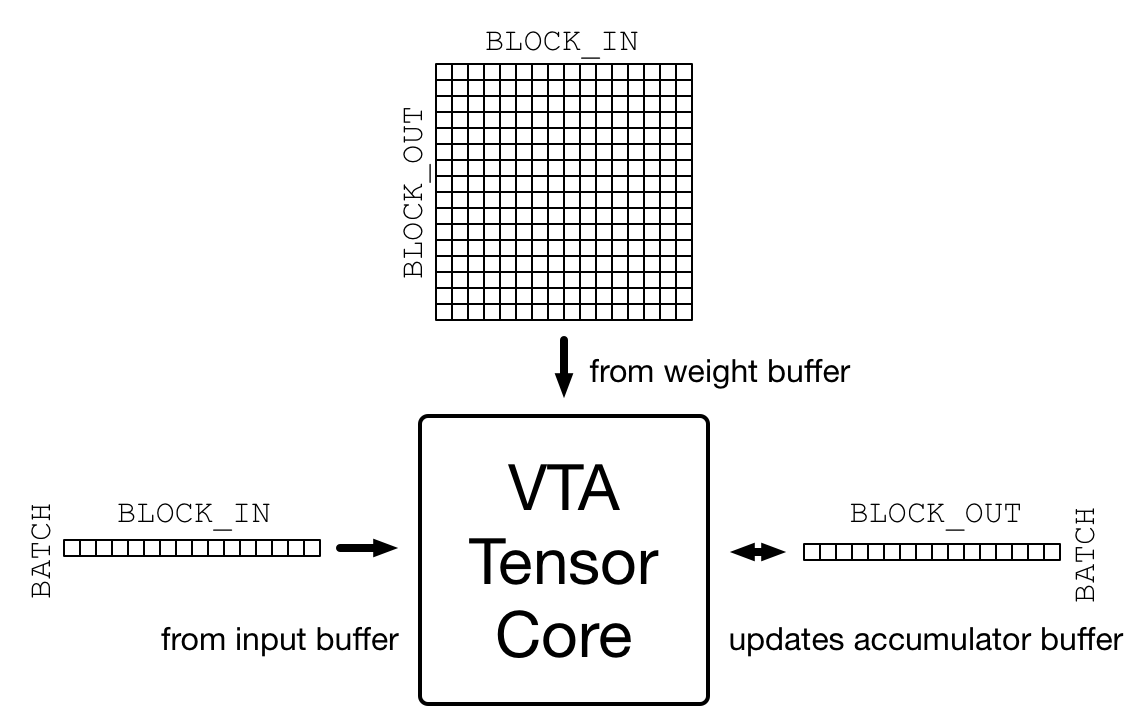
在 vta_config.json 配置文件中指定该矩阵-矩阵乘法的维度。激活矩阵的 shape 为 (BATCH, BLOCK_IN),转置权重矩阵的 shape 为 (BLOCK_OUT, BLOCK_IN),因此推断生成的输出矩阵的 shape 为 (BATCH, BLOCK_OUT)。因此,VTA 处理的输入和输出张量要根据上述维度进行平铺。
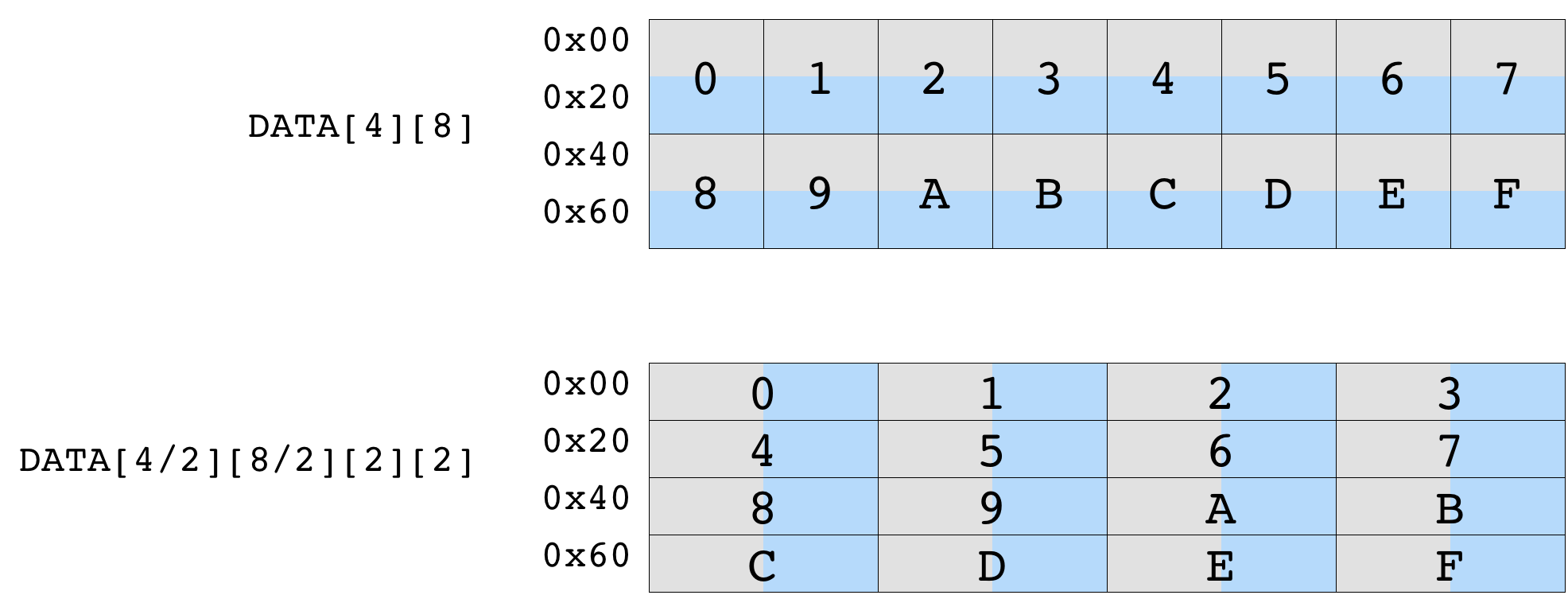
下图展示了数据平铺对初始 shape 为 (4, 8) 的矩阵的影响。按 (2, 2) shape 进行平铺可确保每个平铺内的数据是连续的。生成的平铺张量的 shape 为 (2, 4, 2, 2)。
首先定义变量 m、n、o 来表示矩阵乘法的 shape。这些变量分别是 BLOCK_OUT、BLOCK_IN 和 BATCH 张量维度的乘法因子。配置文件默认将 BATCH、BLOCK_IN 和 BLOCK_OUT 分别设置为 1、16 和 16(BATCH 设置为 1 意味着计算构建块是向量矩阵乘法)。
数据类型
不仅要匹配 VTA 张量 core 的内部平铺维度,还要匹配 VTA 期望的特定数据类型。VTA 目前仅支持固定数据类型,整数宽度在 vta_config.json 文件中指定,INP_WIDTH 和 WGT_WIDTH 分别指定激活和权重数据类型。此外,累加器数据类型的整数宽度由 ACC_WIDTH 指定。
配置文件默认将 INP_WIDTH 和 WGT_WIDTH 设置为 8。将累加器宽度 ACC_WIDTH 设置为 32,避免累加时溢出。因此,env.inp_dtype 和 env.wgt_dtype 都是 8 位窄整数,而 env.acc_dtype 是标准的 32 位整数。
# 输出通道因子 m - 总共 16x16=256 输出通道
m = 16
# 输入通道因子 n - 总共 16x16=256 输入通道
n = 16
# Batch 因子 o (我们使用单一 batch 推断)
o = 1
# A 平铺数据格式的占位符张量
A = te.placeholder((o, n, env.BATCH, env.BLOCK_IN), name="A", dtype=env.inp_dtype))
# B 平铺数据格式的占位符张量
B = te.placeholder((m, n, env.BLOCK_OUT, env.BLOCK_IN), name="B", dtype=env.wgt_dtype))
# A 复制缓冲区
A_buf = te.compute((o, n, env.BATCH, env.BLOCK_IN), lambda *i: A(*i), "A_buf"))
# B 复制缓冲区
B_buf = te.compute((m, n, env.BLOCK_OUT, env.BLOCK_IN), lambda *i: B(*i), "B_buf"))
矩阵乘法
用另一个计算操作来描述矩阵乘法结果张量 C。计算函数采用张量的 shape,以及描述张量每个位置的计算规则的 lambda 函数。
为实现矩阵乘法,lambda 函数要在输入通道维度轴上包含一个归约公式。要创建归约公式,可以用 te.reduce_axis 声明归约轴,它接收归约范围。te.sum 接收要归约的表达式以及归约轴,来计算声明范围内所有 k 值的总和。
注意,要对 32 位 env.acc_dtype 累加器数据类型执行归约。
这个阶段只声明如何进行计算,不会发生任何计算。
# 外部输入特征 reduction 轴
ko = te.reduce_axis((0, n), name="ko")
# 内部输入特征 reduction 轴
ki = te.reduce_axis((0, env.BLOCK_IN), name="ki")
# 描述 in-VTA 矩阵乘法
C_buf = te.compute(
(o, m, env.BATCH, env.BLOCK_OUT),
lambda bo, co, bi, ci: te.sum(
A_buf[bo, ko, bi, ki].astype(env.acc_dtype) * B_buf[co, ko, ci, ki].astype(env.acc_dtype),
axis=[ko, ki],
),
name="C_buf",
)
转换结果
计算完成后,将 VTA 计算的结果送回主存。
内存存储限制
VTA 的一个特点是它只支持窄的 env.inp_dtype 数据类型格式的 DRAM 存储。这可以减少内存传输的数据占用时间,还可以将宽累加器数据类型量化为与输入激活数据类型匹配的数据格式。这意味着在神经网络推理的上下文中,激活后给定层的输出可以直接被下一层利用。
对窄的输入激活数据格式执行最后一个类型转换操作。
# 转换为输出类型,并送到主存
C = te.compute(
(o, m, env.BATCH, env.BLOCK_OUT), lambda *i: C_buf(*i).astype(env.inp_dtype), name="C"
)
本教程的计算声明部分到此结束。
调度计算
虽然上面描述了计算规则,但可以通过多种方式获得 C。 TVM 要求用户提供名为 schedule 的计算实现。
schedule 是对原始计算的一组转换,它在不影响正确性的情况下转换计算的实现。这个简单的 VTA 编程教程旨在演示将原始 schedule 映射到 VTA 硬件原语的基本 schedule 转换。
默认 schedule
构建 schedule 后,schedule 默认以下面的方式计算 C:
# 生成的 schedule
s = te.create_schedule(C.op)
print(tvm.lower(s, [A, B, C], simple_mode=True))
输出结果:
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(int8), int8, [256], []),
B: Buffer(B_2: Pointer(int8), int8, [65536], []),
C: Buffer(C_2: Pointer(int8), int8, [256], [])}
buffer_map = {A_1: A, B_1: B, C_1: C}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, int8, [1, 16, 1, 16], []), B_1: B_3: Buffer(B_2, int8, [16, 16, 16, 16], []), C_1: C_3: Buffer(C_2, int8, [1, 16, 1, 16], [])} {
allocate(A_buf: Pointer(global int8), int8, [256]), storage_scope = global;
allocate(B_buf: Pointer(global int8), int8, [65536]), storage_scope = global;
allocate(C_buf: Pointer(global int32), int32, [256]), storage_scope = global {
for (i1: int32, 0, 16) {
for (i3: int32, 0, 16) {
let cse_var_1: int32 = ((i1*16) + i3)
A_buf_1: Buffer(A_buf, int8, [256], [])[cse_var_1] = A[cse_var_1]
}
}
for (i0: int32, 0, 16) {
for (i1_1: int32, 0, 16) {
for (i2: int32, 0, 16) {
for (i3_1: int32, 0, 16) {
let cse_var_2: int32 = ((((i0*4096) + (i1_1*256)) + (i2*16)) + i3_1)
B_buf_1: Buffer(B_buf, int8, [65536], [])[cse_var_2] = B[cse_var_2]
}
}
}
}
for (co: int32, 0, 16) {
for (ci: int32, 0, 16) {
C_buf_1: Buffer(C_buf, int32, [256], [])[((co*16) + ci)] = 0
for (ko: int32, 0, 16) {
for (ki: int32, 0, 16) {
let cse_var_3: int32 = ((co*16) + ci)
C_buf_1[cse_var_3] = (C_buf_1[cse_var_3] + (cast(int32, A_buf_1[((ko*16) + ki)])*cast(int32, B_buf_1[((((co*4096) + (ko*256)) + (ci*16)) + ki)])))
}
}
}
}
for (i1_2: int32, 0, 16) {
for (i3_2: int32, 0, 16) {
let cse_var_4: int32 = ((i1_2*16) + i3_2)
C[cse_var_4] = cast(int8, C_buf_1[cse_var_4])
}
}
}
}
尽管这个 schedule 有意义,但它不能编译为 VTA。为获得正确的代码生成,要应用调度原语和代码注释,将 schedule 转换为可以直接降级到 VTA 硬件内联函数的 schedule。包括:
- DMA 复制操作将采用全局范围的张量,并将其复制到局部范围的张量中。
- 执行矩阵乘法的张量运算。
缓冲区范围
首先,设置缓冲区的范围,告诉 TVM 这些缓冲区将存在于 VTA 芯片上的 SRAM 缓存中。接下来告诉 TVM,A_buf、B_buf、C_buf 将分别存在于 VTA 芯片上输入、权重和累加器内存中。
VTA 芯片上的 SRAM
VTA 具有三个不同的内存范围,每个范围对应于不同芯片上 SRAM 缓冲区。
env.inp_scope:输入缓冲区,这是一个只读的 SRAM 缓冲区,用于存储env.inp_dtype类型的 shape 为(env.BATCH、env.BLOCK_IN)的输入矩阵。输入缓冲区包含 2 ^ LOG_INP_BUFF_SIZE 矩阵元素(在vta_config.json文件中指定)。env.wgt_scope:权重缓冲区,这是一个只读的 SRAM 缓冲区,用于存储env.wgt_dtype类型的 shape 为(env.BLOCK_OUT,env.BLOCK_IN)的权重矩阵。权重缓冲区包含 2 ^ LOG_WGT_BUFF_SIZE 矩阵元素。env.acc_scope:累加器缓冲区,它是一个读/写 SRAM 缓冲区,用于存储env.acc_dtype类型的 shape 为(env.BATCH, env.BLOCK_OUT)的累加器矩阵。累加器缓冲区是 VTA 的通用寄存器文件:它保存卷积和矩阵乘法的中间结果以及池化、批量归一化和激活层的中间结果。累加器缓冲区包含 2 ^ LOG_ACC_BUFF_SIZE 矩阵元素。
# 将中间张量的范围设置为 VTA 的芯片上缓冲区
s[A_buf].set_scope(env.inp_scope)
s[B_buf].set_scope(env.wgt_scope)
s[C_buf].set_scope(env.acc_scope)
输出结果:
stage(C_buf, compute(C_buf, body=[reduce(combiner=comm_reducer(result=[(x + y)], lhs=[x], rhs=[y], identity_element=[0]), source=[(int32(A_buf[bo, ko, bi, ki])*int32(B_buf[co, ko, ci, ki]))], init=[], axis=[iter_var(ko, range(min=0, ext=16)), iter_var(ki, range(min=0, ext=16))], where=(bool)1, value_index=0)], axis=[iter_var(bo, range(min=0, ext=1)), iter_var(co, range(min=0, ext=16)), iter_var(bi, range(min=0, ext=1)), iter_var(ci, range(min=0, ext=16))], reduce_axis=[iter_var(ko, range(min=0, ext=16)), iter_var(ki, range(min=0, ext=16))], tag=, attrs={}))
DMA 传输
调度 DMA 传输,将 DRAM 中的数据移入和移出 VTA 芯片上的缓冲区。可以用 compute_at 调度原语来实现,该原语将缓冲区的复制嵌套到执行矩阵乘法的计算循环中。
插入 dma_copy 编译指示,向编译器表明复制操作将通过 DMA 批量执行,这在硬件加速器中很常见。最后,打印临时 schedule,观察将复制操作移动到矩阵乘法循环中的效果。
# 将缓冲区副本移动到矩阵乘法循环中
s[A_buf].compute_at(s[C_buf], ko)
s[B_buf].compute_at(s[C_buf], ko)
# 使用 DMA pragma 标记缓冲区拷贝,插入 DMA 传输
s[A_buf].pragma(s[A_buf].op.axis[0], env.dma_copy)
s[B_buf].pragma(s[B_buf].op.axis[0], env.dma_copy)
s[C].pragma(s[C].op.axis[0], env.dma_copy)
# 查看转换后的 schedule
print(tvm.lower(s, [A, B, C], simple_mode=True))
输出结果:
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(int8), int8, [256], []),
B: Buffer(B_2: Pointer(int8), int8, [65536], []),
C: Buffer(C_2: Pointer(int8), int8, [256], [])}
buffer_map = {A_1: A, B_1: B, C_1: C}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, int8, [1, 16, 1, 16], []), B_1: B_3: Buffer(B_2, int8, [16, 16, 16, 16], []), C_1: C_3: Buffer(C_2, int8, [1, 16, 1, 16], [])} {
allocate(C_buf: Pointer(local.acc_buffer int32), int32, [256]), storage_scope = local.acc_buffer;
allocate(A_buf: Pointer(local.inp_buffer int8), int8, [16]), storage_scope = local.inp_buffer;
allocate(B_buf: Pointer(local.wgt_buffer int8), int8, [16]), storage_scope = local.wgt_buffer {
for (co: int32, 0, 16) {
for (ci: int32, 0, 16) {
C_buf_1: Buffer(C_buf, int32, [256], [], scope="local.acc_buffer", align=16)[((co*16) + ci)] = 0
for (ko: int32, 0, 16) {
attr [IterVar(i0: int32, (nullptr), "DataPar", "")] "pragma_dma_copy" = 1;
for (i3: int32, 0, 16) {
A_buf_1: Buffer(A_buf, int8, [16], [], scope="local.inp_buffer", align=16)[i3] = A[((ko*16) + i3)]
}
attr [IterVar(i0_1: int32, (nullptr), "DataPar", "")] "pragma_dma_copy" = 1;
for (i3_1: int32, 0, 16) {
B_buf_1: Buffer(B_buf, int8, [16], [], scope="local.wgt_buffer", align=256)[i3_1] = B[((((co*4096) + (ko*256)) + (ci*16)) + i3_1)]
}
for (ki: int32, 0, 16) {
let cse_var_1: int32 = ((co*16) + ci)
C_buf_1[cse_var_1] = (C_buf_1[cse_var_1] + (cast(int32, A_buf_1[ki])*cast(int32, B_buf_1[ki])))
}
}
}
}
attr [IterVar(i0_2: int32, (nullptr), "DataPar", "")] "pragma_dma_copy" = 1;
for (i1: int32, 0, 16) {
for (i3_2: int32, 0, 16) {
let cse_var_2: int32 = ((i1*16) + i3_2)
C[cse_var_2] = cast(int8, C_buf_1[cse_var_2])
}
}
}
}
张量化
schedule 转换的最后一步是,将张量化应用于 schedule。张量化类似于向量化,只不过将概念扩展到更高维的计算单元。因此,张量化会在声明数据布局输入占位符时,规定数据布局约束,如前所述。我们已经用平铺格式排列了张量,因此接下来对循环重新排序,使其适应张量化。
持续将最外面的 reduction 轴移出。首先要迭代输入通道,然后是 batch 维度,最后是输出通道。最后,沿最内层矩阵-矩阵乘法张量块的外轴应用张量调度原语 tensorize。打印最终的 schedule(即将由 VTA runtime JIT 编译器生成代码):
s[C_buf].reorder(
ko, s[C_buf].op.axis[0], s[C_buf].op.axis[1], s[C_buf].op.axis[2], s[C_buf].op.axis[3], ki
)
s[C_buf].tensorize(s[C_buf].op.axis[2], env.gemm)
# 查看最终确定的 schedule
print(vta.lower(s, [A, B, C], simple_mode=True))
输出结果:
@main = primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"from_legacy_te_schedule": True, "global_symbol": "main", "tir.noalias": True}
buffers = {A: Buffer(A_2: Pointer(int8), int8, [256], []),
B: Buffer(B_2: Pointer(int8), int8, [65536], []),
C: Buffer(C_2: Pointer(int8), int8, [256], [])}
buffer_map = {A_1: A, B_1: B, C_1: C}
preflattened_buffer_map = {A_1: A_3: Buffer(A_2, int8, [1, 16, 1, 16], []), B_1: B_3: Buffer(B_2, int8, [16, 16, 16, 16], []), C_1: C_3: Buffer(C_2, int8, [1, 16, 1, 16], [])} {
attr [IterVar(vta: int32, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushGEMMOp" {
@tir.call_extern("VTAUopLoopBegin", 16, 1, 0, 0, dtype=int32)
@tir.vta.uop_push(0, 1, 0, 0, 0, 0, 0, 0, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 1, dtype=int32)
}
for (ko: int32, 0, 16) {
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 1 {
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), A_2, ko, 1, 1, 1, 0, 0, 0, 0, 0, 2, dtype=int32)
@tir.call_extern("VTALoadBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), B_2, ko, 1, 16, 16, 0, 0, 0, 0, 0, 1, dtype=int32)
@tir.vta.coproc_dep_push(1, 2, dtype=int32)
}
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 2 {
@tir.vta.coproc_dep_pop(1, 2, dtype=int32)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_uop_scope" = "VTAPushGEMMOp" {
@tir.call_extern("VTAUopLoopBegin", 16, 1, 0, 1, dtype=int32)
@tir.vta.uop_push(0, 0, 0, 0, 0, 0, 0, 0, dtype=int32)
@tir.call_extern("VTAUopLoopEnd", dtype=int32)
}
@tir.vta.coproc_dep_push(2, 1, dtype=int32)
}
}
@tir.vta.coproc_dep_push(2, 3, dtype=int32)
@tir.vta.coproc_dep_pop(2, 1, dtype=int32)
attr [IterVar(vta, (nullptr), "ThreadIndex", "vta")] "coproc_scope" = 3 {
@tir.vta.coproc_dep_pop(2, 3, dtype=int32)
@tir.call_extern("VTAStoreBuffer2D", @tir.tvm_thread_context(@tir.vta.command_handle(, dtype=handle), dtype=handle), 0, 4, C_2, 0, 16, 1, 16, dtype=int32)
}
@tir.vta.coproc_sync(, dtype=int32)
}
本教程的调度部分到此结束。
TVM 编译
在完成指定 schedule 后,可将其编译为 TVM 函数。
# 构建 GEMM VTA 内核
my_gemm = vta.build(
s, [A, B, C], tvm.target.Target("ext_dev", host=env.target_host), name="my_gemm"
)
# 将编译后的模块写入目标文件。
temp = utils.tempdir()
my_gemm.save(temp.relpath("gemm.o"))
# 通过 RPC 发送可执行文件
remote.upload(temp.relpath("gemm.o"))
# 加载编译好的模块
f = remote.load_module("gemm.o")
输出结果:
/workspace/python/tvm/driver/build_module.py:267: UserWarning: target_host parameter is going to be deprecated. Please pass in tvm.target.Target(target, host=target_host) instead.
"target_host parameter is going to be deprecated. "
运行函数
编译好的 TVM 函数使用简洁的 C API,可以从代码语言中调用。
TVM 在 Python 中提供了一个基于 DLPack 标准的数组 API,帮助快速测试和原型设计。
- 首先创建一个远程 context(用于在 Pynq 上远程执行)。
- 然后
tvm.nd.array相应地格式化数据。 f()运行实际计算。numpy()以可解释的格式复制结果数组。
# 获取远程设备上下文
ctx = remote.ext_dev(0)
# 在 (-128, 128] 的 int 范围内随机初始化 A 和 B 数组
A_orig = np.random.randint(-128, 128, size=(o * env.BATCH, n * env.BLOCK_IN)).astype(A.dtype)
B_orig = np.random.randint(-128, 128, size=(m * env.BLOCK_OUT, n * env.BLOCK_IN)).astype(B.dtype)
# 将 A 和 B 数组从 2D 打包为 4D 打包布局
A_packed = A_orig.reshape(o, env.BATCH, n, env.BLOCK_IN).transpose((0, 2, 1, 3))
B_packed = B_orig.reshape(m, env.BLOCK_OUT, n, env.BLOCK_IN).transpose((0, 2, 1, 3))
# 用 tvm.nd.array 将输入/输出数组格式化为 DLPack 标准
A_nd = tvm.nd.array(A_packed, ctx)
B_nd = tvm.nd.array(B_packed, ctx)
C_nd = tvm.nd.array(np.zeros((o, m, env.BATCH, env.BLOCK_OUT)).astype(C.dtype), ctx)
# 清除统计
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
# 调用模块进行计算
f(A_nd, B_nd, C_nd)
验证正确性
用 numpy 计算推理结果,得出结论:矩阵乘法的输出是正确的。
# 用 numpy 计算参考结果
C_ref = np.dot(A_orig.astype(env.acc_dtype), B_orig.T.astype(env.acc_dtype)).astype(C.dtype)
C_ref = C_ref.reshape(o, env.BATCH, m, env.BLOCK_OUT).transpose((0, 2, 1, 3))
np.testing.assert_equal(C_ref, C_nd.numpy())
# 打印 stats
if env.TARGET in ["sim", "tsim"]:
sim_stats = simulator.stats()
print("Execution statistics:")
for k, v in sim_stats.items():
print("\t{:<16}: {:>16}".format(k, v))
print("Successful matrix multiply test!")
输出结果:
Execution statistics:
inp_load_nbytes : 256
wgt_load_nbytes : 65536
acc_load_nbytes : 0
uop_load_nbytes : 8
out_store_nbytes: 256
gemm_counter : 256
alu_counter : 0
Successful matrix multiply test!
总结
本教程展示了在 VTA 上实现简单矩阵乘法示例的 TVM 工作流程。一般工作流程包括:
- 通过 RPC 使用 VTA 比特流对 FPGA 进行编程。
- 通过一系列计算描述矩阵乘法。
- 描述希望如何用调度原语执行计算。
- 将函数编译为 VTA target。
- 运行编译好的模块,并根据 numpy 实现进行验证。