在 VTA 上部署来自 Darknet 的预训练视觉检测模型
备注
单击 此处 下载完整的示例代码
作者:Hua Jiang
本教程提供了一个端到端 demo,介绍了如何在 VTA 加速器设计上运行 Darknet YoloV3-tiny 推理,执行图像检测任务。它展示了 Relay 作为一个前端编译器,可以执行量化(VTA 仅支持 int8/32 推理)以及计算图打包(为了在 core 中启用张量),从而为硬件 target 修改计算图。
安装依赖
要在 TVM 中使用 autotvm 包,需要安装额外的依赖(如果用的是 Python2,请将「3」更改为「2」):
pip3 install "Pillow<7"
支持 Darknet 解析的 YOLO-V3-tiny 模型依赖于 CFFI 和 CV2 库,因此要在执行此脚本之前安装 CFFI 和 CV2。
pip3 install cffi
pip3 install opencv-python
在 Python 代码中导入包:
from __future__ import absolute_import, print_function
import sys
import os
import time
import matplotlib.pyplot as plt
import numpy as np
import tvm
import vta
from tvm import rpc, autotvm, relay
from tvm.relay.testing import yolo_detection, darknet
from tvm.relay.testing.darknet import __darknetffi__
from tvm.contrib import graph_executor, utils
from tvm.contrib.download import download_testdata
from vta.testing import simulator
from vta.top import graph_pack
# 确保 TVM 是使用 RPC=1 编译的
assert tvm.runtime.enabled("rpc")
根据 Model Name 下载 yolo net 配置文件、权重文件、Darknet 库文件 ———————————————————————————-
MODEL_NAME = "yolov3-tiny"
REPO_URL = "https://github.com/dmlc/web-data/blob/main/darknet/"
cfg_path = download_testdata(
"https://github.com/pjreddie/darknet/blob/master/cfg/" + MODEL_NAME + ".cfg" + "?raw=true",
MODEL_NAME + ".cfg",
module="darknet",
)
weights_path = download_testdata(
"https://pjreddie.com/media/files/" + MODEL_NAME + ".weights" + "?raw=true",
MODEL_NAME + ".weights",
module="darknet",
)
if sys.platform in ["linux", "linux2"]:
darknet_lib_path = download_testdata(
REPO_URL + "lib/" + "libdarknet2.0.so" + "?raw=true", "libdarknet2.0.so", module="darknet"
)
elif sys.platform == "darwin":
darknet_lib_path = download_testdata(
REPO_URL + "lib_osx/" + "libdarknet_mac2.0.so" + "?raw=true",
"libdarknet_mac2.0.so",
module="darknet",
)
else:
raise NotImplementedError("Darknet lib is not supported on {} platform".format(sys.platform))
下载 YOLO 标签名称和对应插图
coco_path = download_testdata(
REPO_URL + "data/" + "coco.names" + "?raw=true", "coco.names", module="data"
)
font_path = download_testdata(
REPO_URL + "data/" + "arial.ttf" + "?raw=true", "arial.ttf", module="data"
)
with open(coco_path) as f:
content = f.readlines()
names = [x.strip() for x in content]
定义平台和模型 target
对比在 CPU 与 VTA 上执行,并定义模型。
# 从 3rdparty/vta-hw/config/vta_config.json 文件加载 VTA 参数
env = vta.get_env()
# 设置 ``device=arm_cpu``,在 CPU 上运行推理
# 设置 ``device=vta`` 在 FPGA 上运行推理
device = "vta"
target = env.target if device == "vta" else env.target_vta_cpu
pack_dict = {
"yolov3-tiny": ["nn.max_pool2d", "cast", 4, 186],
}
# 要编译的 Darknet 模型的名称
# ``start_pack`` 和 ``stop_pack`` 标签指示在哪里开始和结束计算图打包 Relay pass:换句话说,从哪里开始和结束转移到 VTA。
# 数字 4 表示 ``start_pack`` 索引是 4,数字 186 表示 ``stop_pack 索引`` 是 186,通过使用名称和索引号,可以在这里找到正确的开始/结束的位置是多个 ``nn.max_pool2d`` 或 ``cast``, print(mod.astext(show_meta_data=False)) 可以帮助查找算子名称和索引信息。
assert MODEL_NAME in pack_dict
获取远程执行
当 target 是「pynq」或其他 FPGA 后端时,重新配置 FPGA 和 runtime。若 target 是「sim」,则在本地执行。
if env.TARGET not in ["sim", "tsim"]:
# 若设置了环境变量,则从跟踪器节点获取远程。
# 要设置跟踪器,你需要遵循「为 VTA 自动调优卷积网络」教程。
tracker_host = os.environ.get("TVM_TRACKER_HOST", None)
tracker_port = os.environ.get("TVM_TRACKER_PORT", None)
# 否则,若有一个想要直接从主机编程的设备,请确保已将以下变量设置为你的板子的 IP。
device_host = os.environ.get("VTA_RPC_HOST", "192.168.2.99")
device_port = os.environ.get("VTA_RPC_PORT", "9091")
if not tracker_host or not tracker_port:
remote = rpc.connect(device_host, int(device_port))
else:
remote = autotvm.measure.request_remote(
env.TARGET, tracker_host, int(tracker_port), timeout=10000
)
# 重新配置 JIT runtime 和 FPGA
# 可以通过将路径传递给比特流文件,而非 None,使用自定义比特流对 FPGA 进行编程。
reconfig_start = time.time()
vta.reconfig_runtime(remote)
vta.program_fpga(remote, bitstream=None)
reconfig_time = time.time() - reconfig_start
print("Reconfigured FPGA and RPC runtime in {0:.2f}s!".format(reconfig_time))
# 在模拟模式下,本地托管 RPC 服务器。
else:
remote = rpc.LocalSession()
# 从远程获取执行上下文
ctx = remote.ext_dev(0) if device == "vta" else remote.cpu(0)
构建推理图执行器
用 Darknet 库加载下载的视觉模型,并用 Relay 编译。编译步骤如下:
- 从 Darknet 到 Relay 模块的前端转换。
- 应用 8 位量化:这里跳过第一个 conv 层和 dense 层,它们都将在 CPU 上以 fp32 执行。
- 执行计算图打包,更改张量化的数据布局。
- 执行常量折叠,减少算子的数量(例如,消除 batch norm multiply)。
- 对目标文件执行 Relay 构建。
- 将目标文件加载到远程(FPGA 设备)。
- 生成图执行器 m。
# 加载预先配置的 AutoTVM schedule
with autotvm.tophub.context(target):
net = __darknetffi__.dlopen(darknet_lib_path).load_network(
cfg_path.encode("utf-8"), weights_path.encode("utf-8"), 0
)
dshape = (env.BATCH, net.c, net.h, net.w)
dtype = "float32"
# 测试构建开始时间
build_start = time.time()
# 开始前端编译
mod, params = relay.frontend.from_darknet(net, dtype=dtype, shape=dshape)
if target.device_name == "vta":
# 在 Relay 中执行量化
# 注意:将 opt_level 设置为 3,折叠 batch norm
with tvm.transform.PassContext(opt_level=3):
with relay.quantize.qconfig(
global_scale=23.0,
skip_conv_layers=[0],
store_lowbit_output=True,
round_for_shift=True,
):
mod = relay.quantize.quantize(mod, params=params)
# 对 VTA target 进行计算图打包和常量折叠
mod = graph_pack(
mod["main"],
env.BATCH,
env.BLOCK_OUT,
env.WGT_WIDTH,
start_name=pack_dict[MODEL_NAME][0],
stop_name=pack_dict[MODEL_NAME][1],
start_name_idx=pack_dict[MODEL_NAME][2],
stop_name_idx=pack_dict[MODEL_NAME][3],
)
else:
mod = mod["main"]
# 在禁用 AlterOpLayout 的情况下,编译 Relay 程序
with vta.build_config(disabled_pass={"AlterOpLayout", "tir.CommonSubexprElimTIR"}):
lib = relay.build(
mod, target=tvm.target.Target(target, host=env.target_host), params=params
)
# 测试 Relay 构建时间
build_time = time.time() - build_start
print(MODEL_NAME + " inference graph built in {0:.2f}s!".format(build_time))
# 将推理库发送到远程 RPC 服务器
temp = utils.tempdir()
lib.export_library(temp.relpath("graphlib.tar"))
remote.upload(temp.relpath("graphlib.tar"))
lib = remote.load_module("graphlib.tar")
# 图执行器
m = graph_executor.GraphModule(lib["default"](ctx))
输出结果:
/workspace/python/tvm/driver/build_module.py:267: UserWarning: target_host parameter is going to be deprecated. Please pass in tvm.target.Target(target, host=target_host) instead.
"target_host parameter is going to be deprecated. "
/workspace/python/tvm/relay/build_module.py:411: DeprecationWarning: Please use input parameter mod (tvm.IRModule) instead of deprecated parameter mod (tvm.relay.function.Function)
DeprecationWarning,
yolov3-tiny inference graph built in 16.12s!
执行图像检测推理
在下载的测试图像上运行检测
[neth, netw] = dshape[2:]
test_image = "person.jpg"
img_url = REPO_URL + "data/" + test_image + "?raw=true"
img_path = download_testdata(img_url, test_image, "data")
data = darknet.load_image(img_path, neth, netw).transpose(1, 2, 0)
# 为推理准备测试图像
plt.imshow(data)
plt.show()
data = data.transpose((2, 0, 1))
data = data[np.newaxis, :]
data = np.repeat(data, env.BATCH, axis=0)
# 设置网络参数和输入
m.set_input("data", data)
# 执行推理,并收集执行统计信息
# 更多信息::py:method:`tvm.runtime.Module.time_evaluator`
num = 4 # 单次测试运行模块的次数
rep = 3 # 测试次数(我们从中得出标准差)
timer = m.module.time_evaluator("run", ctx, number=num, repeat=rep)
if env.TARGET in ["sim", "tsim"]:
simulator.clear_stats()
timer()
sim_stats = simulator.stats()
print("\nExecution statistics:")
for k, v in sim_stats.items():
# 由于我们多次执行工作负载,我们需要标准化统计信息
# 注意,总是有一个预热
# 因此将整体统计数据除以 (num * rep + 1)
print("\t{:<16}: {:>16}".format(k, v // (num * rep + 1)))
else:
tcost = timer()
std = np.std(tcost.results) * 1000
mean = tcost.mean * 1000
print("\nPerformed inference in %.2fms (std = %.2f) for %d samples" % (mean, std, env.BATCH))
print("Average per sample inference time: %.2fms" % (mean / env.BATCH))
# 从 out 获取检测结果
thresh = 0.5
nms_thresh = 0.45
tvm_out = []
for i in range(2):
layer_out = {}
layer_out["type"] = "Yolo"
# 获取 yolo 层的属性 (n、out_c、out_h、out_w、classes、total)
layer_attr = m.get_output(i * 4 + 3).numpy()
layer_out["biases"] = m.get_output(i * 4 + 2).numpy()
layer_out["mask"] = m.get_output(i * 4 + 1).numpy()
out_shape = (layer_attr[0], layer_attr[1] // layer_attr[0], layer_attr[2], layer_attr[3])
layer_out["output"] = m.get_output(i * 4).numpy().reshape(out_shape)
layer_out["classes"] = layer_attr[4]
tvm_out.append(layer_out)
thresh = 0.560
# 显示检测结果
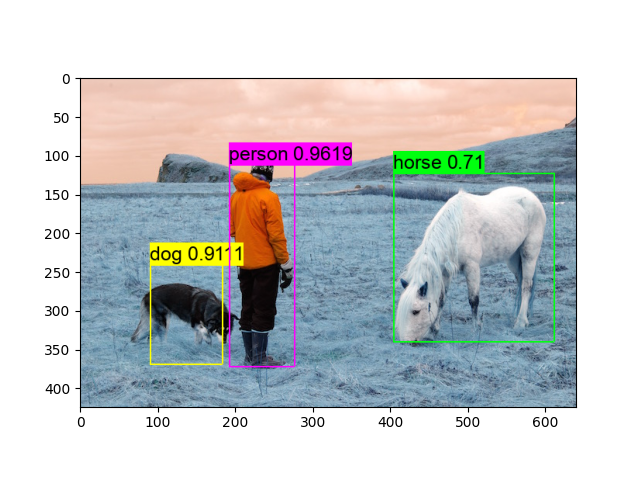
img = darknet.load_image_color(img_path)
_, im_h, im_w = img.shape
dets = yolo_detection.fill_network_boxes((netw, neth), (im_w, im_h), thresh, 1, tvm_out)
last_layer = net.layers[net.n - 1]
yolo_detection.do_nms_sort(dets, last_layer.classes, nms_thresh)
yolo_detection.draw_detections(font_path, img, dets, thresh, names, last_layer.classes)
plt.imshow(img.transpose(1, 2, 0))
plt.show()
Execution statistics:
inp_load_nbytes : 25462784
wgt_load_nbytes : 17558016
acc_load_nbytes : 96128
uop_load_nbytes : 5024
out_store_nbytes: 3396224
gemm_counter : 10578048
alu_counter : 849056