自定义优化
本教程可通过 Google Colab 交互式运行!也可点击此处在本地运行 Jupyter Notebook。
Apache TVM 的一个主要设计目标是便于自定义优化流程,无论是用于科研探索还是工程开发,都可以灵活迭代优化过程。本教程将涵盖以下内容:
目录
审查整体流程
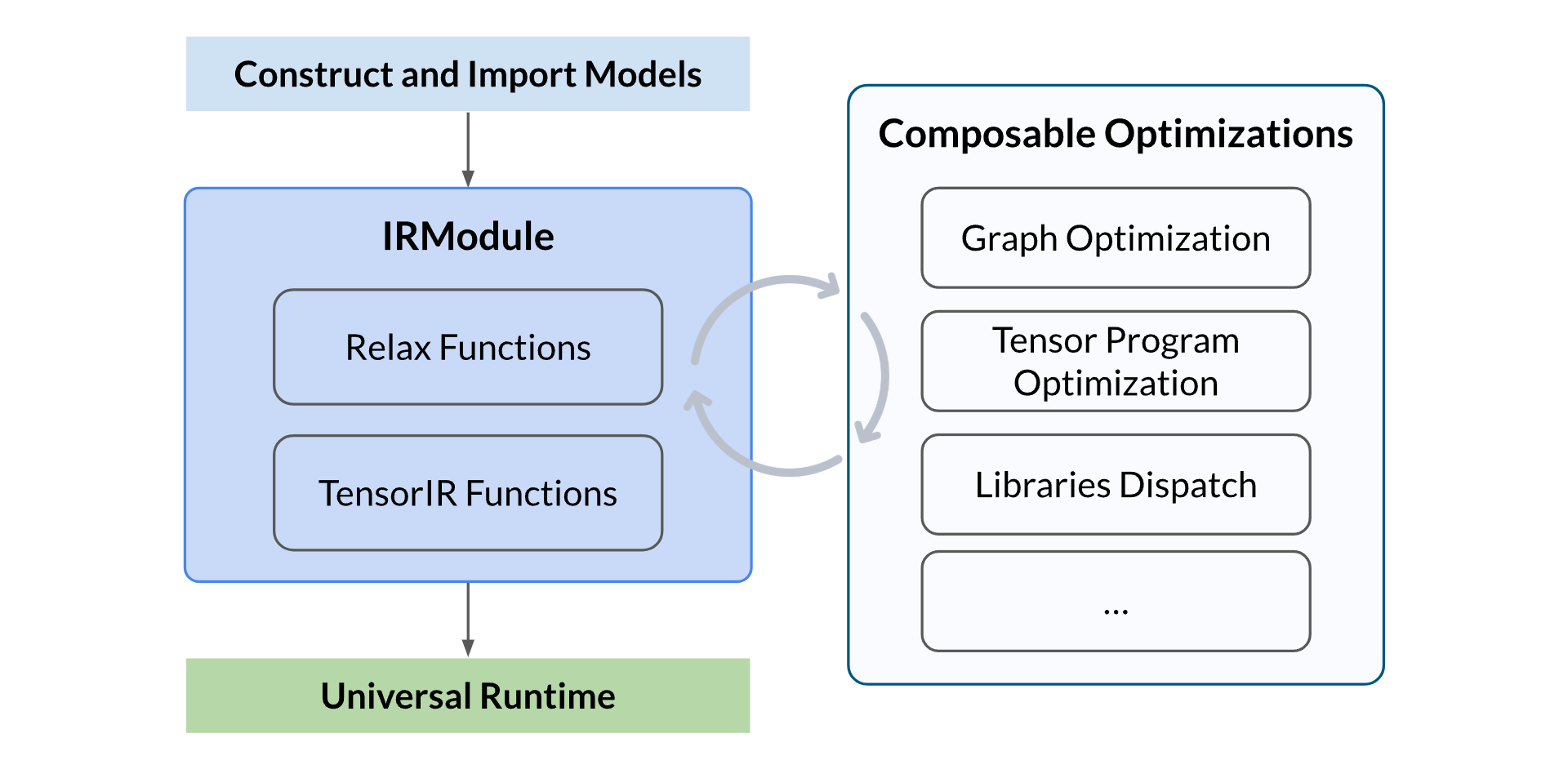
整体流程包括以下几个步骤:
- 构建或导入模型:可以手动构建一个神经网络模型,或从其他框架(如 PyTorch、ONNX)中导入一个预训练模型,并生成 TVM 的 IRModule。该模块包含编译所需的所有信息,包括用于表示计算图的高层 Relax 函数,以及用于描述张量程序的低层 TensorIR 函数
- 执行可组合优化:执行一系列优化转换,包括计算图优化、张量程序优化和算子调度/分发等
- 构建并进行通用部署:将优化后的模型构建为可部署模块,使用 TVM 通用运行时在不同设备上运行,例如 CPU、GPU 或其他加速器
import os
import tempfile
import numpy as np
import tvm
from tvm import IRModule, relax
from tvm.relax.frontend import nn
可组合的 IRModule 优化
Apache TVM Unity 提供了一种灵活的方式来优化 IRModule。围绕 IRModule 的所有优化都可以与现有的编译流水线进行组合。值得注意的是, 每个优化步骤可以只关注计算图的一部分, 从而实现局部下沉或局部优化。
在本教程中,我们将演示如何使用 Apache TVM Unity 优化模型。
准备 Relax 模块
我们首先准备一个 Relax 模块。该模块可以通过从其他框架导入、使用神经网络前端构建,或直接使用 TVMScript 来创建。这里我们以一个简单的神经网络模型为例。
class RelaxModel(nn.Module):
def __init__(self):
super(RelaxModel, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(256, 10, bias=False)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
return x
input_shape = (1, 784)
mod, params = RelaxModel().export_tvm({"forward": {"x": nn.spec.Tensor(input_shape, "float32")}})
mod.show()
输出:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
with R.dataflow():
permute_dims: R.Tensor((784, 256), dtype="float32") = R.permute_dims(fc1_weight, axes=None)
matmul: R.Tensor((1, 256), dtype="float32") = R.matmul(x, permute_dims, out_dtype="void")
add: R.Tensor((1, 256), dtype="float32") = R.add(matmul, fc1_bias)
relu: R.Tensor((1, 256), dtype="float32") = R.nn.relu(add)
permute_dims1: R.Tensor((256, 10), dtype="float32") = R.permute_dims(fc2_weight, axes=None)
matmul1: R.Tensor((1, 10), dtype="float32") = R.matmul(relu, permute_dims1, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = matmul1
R.output(gv)
return gv
库调度
我们希望能够快速在特定平台(例如 GPU)上尝试某种库优化的变体。我们可以为特定平台和算子编写专属的调度 pass。这里我们将展示如何为某些模式调度 CUBLAS 库。
本教程仅演示了一个针对 CUBLAS 的单个算子调度,用于突出优化流程的灵活性。在实际案例中,我们可以导入多个模式,并将它们分别调度到不同的内核中。
# 导入 cublas 模式
import tvm.relax.backend.cuda.cublas as _cublas
# 定义一个用于 CUBLAS 调度的新 pass
@tvm.transform.module_pass(opt_level=0, name="CublasDispatch")
class CublasDispatch:
def transform_module(self, mod: IRModule, _ctx: tvm.transform.PassContext) -> IRModule:
# 检查是否启用了 CUBLAS
if not tvm.get_global_func("relax.ext.cublas", True):
raise Exception("CUBLAS is not enabled.")
# 获取目标匹配模式
patterns = [relax.backend.get_pattern("cublas.matmul_transposed_bias_relu")]
# 注意,在实际情况中,通常会获取所有以 "cublas" 开头的模式
# patterns = relax.backend.get_patterns_with_prefix("cublas")
# 按照模式融合操作,并运行代码生成
mod = relax.transform.FuseOpsByPattern(patterns, annotate_codegen=True)(mod)
mod = relax.transform.RunCodegen()(mod)
return mod
mod = CublasDispatch()(mod)
mod.show()
输出:
# from tvm.script import ir as I
# from tvm.script import relax as R
@I.ir_module
class Module:
I.module_attrs({"external_mods": [metadata["ffi.Module"][0]]})
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
with R.dataflow():
lv = R.call_dps_packed("fused_relax_permute_dims_relax_matmul_relax_add_relax_nn_relu_cublas", (fc1_weight, x, fc1_bias), out_sinfo=R.Tensor((1, 256), dtype="float32"))
permute_dims1: R.Tensor((256, 10), dtype="float32") = R.permute_dims(fc2_weight, axes=None)
matmul1: R.Tensor((1, 10), dtype="float32") = R.matmul(lv, permute_dims1, out_dtype="void")
gv: R.Tensor((1, 10), dtype="float32") = matmul1
R.output(gv)
return gv
# 元数据被省略。要显示元数据,请在 script() 方法中使用 show_meta=True。
在执行调度 pass 后,我们可以看到原始的 nn.Linear 和 nn.ReLU 已被融合,并重写为调用 CUBLAS 库的 call_dps_packed 函数。值得注意的是,计算图中的其他部分并未改变,这意味着我们可以选择性地对某些计算部分进行优化调度。
自动调优
接着前面的例子,我们可以通过自动调优进一步优化模型剩余的计算部分, 这里我们演示如何使用 Meta Schedule 对模型进行自动调优。
我们可以使用 MetaScheduleTuneTIR Pass 来对模型进行简单的调优,而使用 MetaScheduleApplyDatabase Pass 则可以将最优配置应用到模型中。调优过程会生成搜索空间,对模型进行调优,随后将最优配置应用到模型中。在运行这些 Pass 之前,我们需要通过 LegalizeOps 将 relax 操作符下沉为 TensorIR 函数。
为了节省 CI 时间并避免波动性,我们在 CI 环境中跳过了调优过程。
device = tvm.cuda(0)
target = tvm.target.Target.from_device(device)
if os.getenv("CI", "") != "true":
trials = 2000
with target, tempfile.TemporaryDirectory() as tmp_dir:
mod = tvm.ir.transform.Sequential(
[
relax.get_pipeline("zero"),
relax.transform.MetaScheduleTuneTIR(work_dir=tmp_dir, max_trials_global=trials),
relax.transform.MetaScheduleApplyDatabase(work_dir=tmp_dir),
]
)(mod)
mod.show()
DLight 规则
DLight 规则是一组用于调度和优化内核的默认规则。DLight 规则设计的目标是快速编译与公平性能的折中。 在某些场景(例如语言模型)下,DLight 能提供非常优秀的性能;而在通用模型场景中,则更注重性能与编译时间之间的平衡。
from tvm import dlight as dl
# 应用 DLight 规则
with target:
mod = tvm.ir.transform.Sequential(
[
relax.get_pipeline("zero"),
dl.ApplyDefaultSchedule( # pylint: disable=not-callable
dl.gpu.Matmul(),
dl.gpu.GEMV(),
dl.gpu.Reduction(),
dl.gpu.GeneralReduction(),
dl.gpu.Fallback(),
),
]
)(mod)
mod.show()
输出:
# from tvm.script import ir as I
# from tvm.script import tir as T
# from tvm.script import relax as R
@I.ir_module
class Module:
I.module_attrs({"external_mods": [metadata["ffi.Module"][0]]})
@T.prim_func(private=True)
def matmul(lv: T.Buffer((T.int64(1), T.int64(256)), "float32"), permute_dims1: T.Buffer((T.int64(256), T.int64(10)), "float32"), matmul: T.Buffer((T.int64(1), T.int64(10)), "float32")):
T.func_attr({"op_pattern": 4, "tir.is_scheduled": True, "tir.noalias": True})
# with T.block("root"):
matmul_rf_local = T.alloc_buffer((T.int64(16), T.int64(1), T.int64(10)), scope="local")
for ax0_fused_0 in T.thread_binding(T.int64(1), thread="blockIdx.x"):
for ax0_fused_1 in T.thread_binding(T.int64(10), thread="threadIdx.x"):
for ax1_fused_1 in T.thread_binding(T.int64(16), thread="threadIdx.y"):
with T.block("matmul_rf_init"):
vax1_fused_1 = T.axis.spatial(T.int64(16), ax1_fused_1)
v0 = T.axis.spatial(T.int64(10), ax0_fused_0 * T.int64(10) + ax0_fused_1)
T.reads()
T.writes(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
matmul_rf_local[vax1_fused_1, T.int64(0), v0] = T.float32(0.0)
for ax1_fused_0, u in T.grid(T.int64(16), 1):
with T.block("matmul_rf_update"):
vax1_fused_1 = T.axis.spatial(T.int64(16), ax1_fused_1)
v0 = T.axis.spatial(T.int64(10), ax0_fused_0 * T.int64(10) + ax0_fused_1)
vax1_fused_0 = T.axis.reduce(T.int64(16), ax1_fused_0)
T.reads(matmul_rf_local[vax1_fused_1, T.int64(0), v0], lv[T.int64(0), vax1_fused_0 * T.int64(16) + vax1_fused_1], permute_dims1[vax1_fused_0 * T.int64(16) + vax1_fused_1, v0])
T.writes(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
matmul_rf_local[vax1_fused_1, T.int64(0), v0] = matmul_rf_local[vax1_fused_1, T.int64(0), v0] + lv[T.int64(0), vax1_fused_0 * T.int64(16) + vax1_fused_1] * permute_dims1[vax1_fused_0 * T.int64(16) + vax1_fused_1, v0]
for ax1_fused in T.thread_binding(T.int64(10), thread="threadIdx.x"):
for ax0 in T.thread_binding(T.int64(16), thread="threadIdx.y"):
with T.block("matmul"):
vax1_fused_1, v0 = T.axis.remap("RS", [ax0, ax1_fused])
T.reads(matmul_rf_local[vax1_fused_1, T.int64(0), v0])
T.writes(matmul[T.int64(0), v0])
with T.init():
matmul[T.int64(0), v0] = T.float32(0.0)
matmul[T.int64(0), v0] = matmul[T.int64(0), v0] + matmul_rf_local[vax1_fused_1, T.int64(0), v0]
@T.prim_func(private=True)
def transpose(fc2_weight: T.Buffer((T.int64(10), T.int64(256)), "float32"), T_transpose: T.Buffer((T.int64(256), T.int64(10)), "float32")):
T.func_attr({"op_pattern": 2, "tir.is_scheduled": True, "tir.noalias": True})
# with T.block("root"):
for ax0_ax1_fused_0 in T.thread_binding(T.int64(3), thread="blockIdx.x"):
for ax0_ax1_fused_1 in T.thread_binding(T.int64(1024), thread="threadIdx.x"):
with T.block("T_transpose"):
v0 = T.axis.spatial(T.int64(256), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) // T.int64(10))
v1 = T.axis.spatial(T.int64(10), (ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1) % T.int64(10))
T.where(ax0_ax1_fused_0 * T.int64(1024) + ax0_ax1_fused_1 < T.int64(2560))
T.reads(fc2_weight[v1, v0])
T.writes(T_transpose[v0, v1])
T_transpose[v0, v1] = fc2_weight[v1, v0]
@R.function
def forward(x: R.Tensor((1, 784), dtype="float32"), fc1_weight: R.Tensor((256, 784), dtype="float32"), fc1_bias: R.Tensor((256,), dtype="float32"), fc2_weight: R.Tensor((10, 256), dtype="float32")) -> R.Tensor((1, 10), dtype="float32"):
R.func_attr({"num_input": 1})
cls = Module
with R.dataflow():
lv = R.call_dps_packed("fused_relax_permute_dims_relax_matmul_relax_add_relax_nn_relu_cublas", (fc1_weight, x, fc1_bias), out_sinfo=R.Tensor((1, 256), dtype="float32"))
permute_dims1 = R.call_tir(cls.transpose, (fc2_weight,), out_sinfo=R.Tensor((256, 10), dtype="float32"))
gv = R.call_tir(cls.matmul, (lv, permute_dims1), out_sinfo=R.Tensor((1, 10), dtype="float32"))
R.output(gv)
return gv
# Metadata omitted. Use show_meta=True in script() method to show it.
本教程的重点是展示优化流程,而不是将性能推至极限。因此当前的优化策略可能并非最佳配置。
部署优化后的模型
我们可以将优化后的模型构建并部署到 TVM 的运行时中。
ex = tvm.compile(mod, target="cuda")
dev = tvm.device("cuda", 0)
vm = relax.VirtualMachine(ex, dev)
# 需要在 GPU 设备上分配数据和参数
data = tvm.runtime.tensor(np.random.rand(*input_shape).astype("float32"), dev)
gpu_params = [tvm.runtime.tensor(np.random.rand(*p.shape).astype(p.dtype), dev) for _, p in params]
gpu_out = vm["forward"](data, *gpu_params).numpy()
print(gpu_out)
输出:
[[26357.13 23372.246 25534.104 26006.512 23795.57 24571.258 25749.385
23908.93 26135.215 25507.008]]
总结
本教程展示了如何在 Apache TVM 中自定义机器学习模型的优化流程。我们可以轻松组合优化 pass,并针对计算图中的不同部分定制优化策略。优化流程的高度灵活性使我们能够快速迭代优化步骤,从而提升模型性能(可右键另存为下载)。