TVM 运行时系统
TVM 支持多种编程语言用于编译器栈的开发和部署。在本说明中,我们将解释 TVM 运行时的关键组成部分。
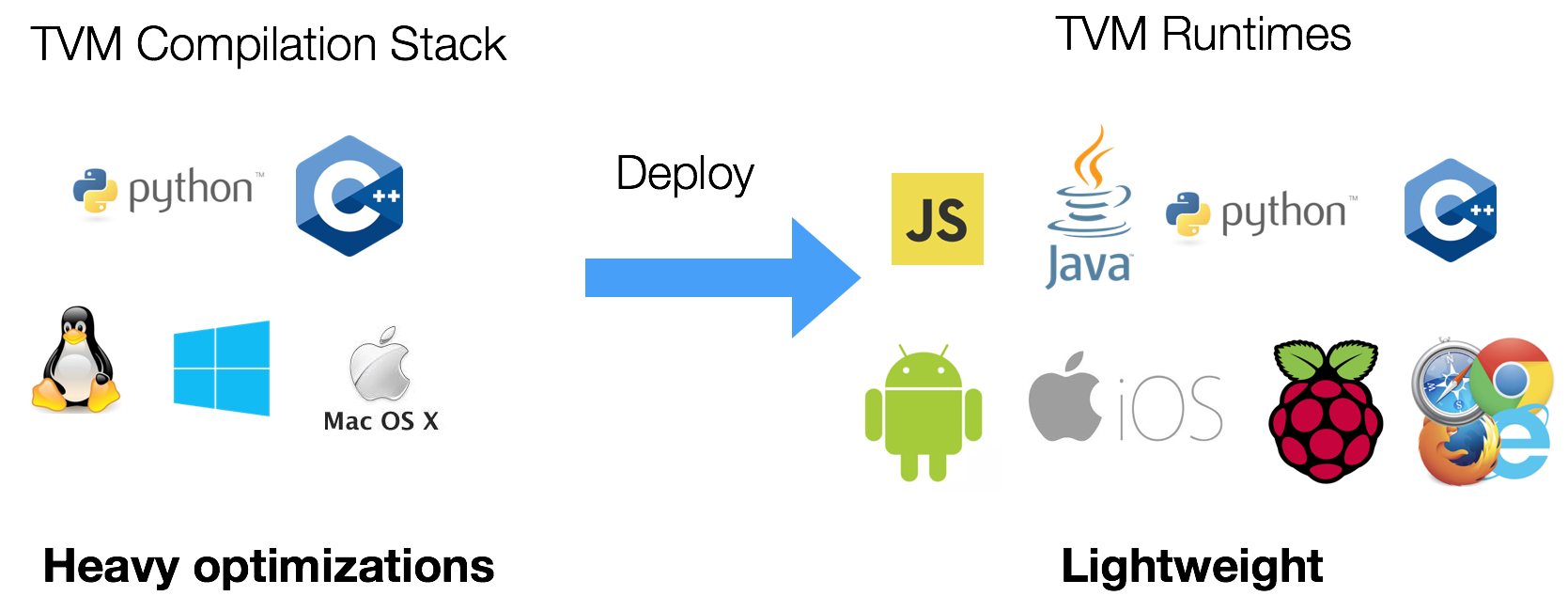
VM 的运行时系统需要满足多种看似相互矛盾但又非常关键的需求:
-
部署(Deployment):能够在 Python / JavaScript / C++ 等语言中调用已编译的函数。
-
调试(Debug):允许用户在 Python 中定义函数,并从已编译的代码中反向调用。
-
链接(Linking):需要编写驱动端代码来调用设备端实现(如 CUDA kernel),并且运行时需要能从主机端代码中调用它们。
-
原型开发(Prototyping):支持在 Python 中创建 IR Pass,并能从 C++ 后端调用。
-
接口暴露(Frontend Exposure):编译器的核心逻辑由 C++ 实现,但必须便捷地暴露给 Python 等前端语言。
-
实验与部署(Experiment & Deployment):能够将编译好的函数直接传输并运行在嵌入式设备上。
我们希望能够在任何语言中定义函数并在另一种语言中调用。我们还希望运行时核心尽可能小,以便部署到嵌入式设备上。
PackedFunc
PackedFunc是我们找到的一个简单但优雅的解决方案来解决列出的挑战。
一个 PackedFunc 对象就表示一次函数调用,而调用方和被调用方可以处于不同的语言环境中。
下面的代码块提供了一个 C++ 示例
#include <tvm/ffi/function.h>
void MyAdd(ffi::PackedArgs args, ffi::Any* rv) {
// automatically convert arguments to desired type.
int a = args[0].cast<int>();
int b = args[1].cast<int>();
// automatically assign value return to rv
*rv = a + b;
}
void CallPacked() {
PackedFunc myadd = PackedFunc(MyAdd);
// get back 3
int c = myadd(1, 2);
}
在上面的代码块中,我们定义了一个 PackedFunc MyAdd。它接受两个参数:args 表示输入参数,rv 表示返回值。该函数是类型擦除的,这意味着函数签名不会限制传入或返回值的类型。在底层,当我们调用一个 PackedFunc 时,它会将输入参数打包成 ffi::PackedArgs 放在栈上,并通过 ffi::Any 获取返回结果。
得益于 C++ 中的模板机制,我们可以像调用普通函数一样调用 PackedFunc。由于其类型擦除的特性,我们可以在诸如 Python 这样的动态语言中调用 PackedFunc,而不需要为每一种新函数类型额外编写 glue 代码。下面的例子展示了如何在 C++ 中注册一个 PackedFunc,并在 Python 中调用它。
// register a global packed function in c++
TVM_FFI_STATIC_INIT_BLOCK() {
namespace refl = tvm::ffi::reflection;
refl::GlobalDef().def_packed("myadd", MyAdd);
}
import tvm
myadd = tvm.get_global_func("myadd")
# prints 3
print(myadd(1, 2))
PackedFunc 的大部分「魔力」来自 ffi::PackedArgs 和 ffi::Any 这两个结构。我们对可传递的类型做了限制,常见的类型包括:
-
int、float 和 string
-
PackedFunc 本身
-
Module,用于表示已编译模块
-
DLTensor*,用于张量对象交换
-
TVM Object,用于表示 IR 中的任意对象
这种限制使得实现变得简单,无需序列化。即使实现精简,PackedFunc 在深度学习部署的场景中依然绰绰有余,因为大多数函数只需要处理 DLTensor 或数字。
由于一个 PackedFunc 可以将另一个 PackedFunc 作为参数传递,因此我们可以将 Python 中的函数(转换为 PackedFunc)传递给 C++。
TVM_FFI_STATIC_INIT_BLOCK() {
namespace refl = tvm::ffi::reflection;
refl::GlobalDef().def_packed("callhello", [](ffi::PackedArgs args, ffi::Any* rv) {
ffi::Function f = args[0].cast<ffi::Function>();
f("hello world");
});
}
import tvm
def callback(msg):
print(msg)
# convert to PackedFunc
f = tvm.convert(callback)
callhello = tvm.get_global_func("callhello")
# prints hello world
callhello(f)
TVM 提供了一个最小化的 C API minimum C API,它允许我们将 PackedFunc 嵌入到任意语言中。除了 Python 以外,目前还支持 java 和 javascript。这种嵌入式 API 的设计理念与 Lua 很相似,只不过我们并没有创造一门新的语言,而是直接使用了 C++。
关于 PackedFunc 有一个有趣的事实:我们在编译器栈和部署栈中都使用它。
-
TVM 中所有编译器 Pass 函数都以 PackedFunc 的形式暴露给前端
-
已编译模块同样以 PackedFunc 的形式返回已生成的函数
为了保持运行时尽可能精简,我们将 IR Object 支持从部署运行时中分离开来。最终生成的运行时大小大约为 200K - 600K,具体取决于包含的运行时驱动模块数量(例如 CUDA)。
调用 PackedFunc 相比普通函数的开销很小,只多做了一些栈上值保存。因此,只要不频繁包装非常小的函数,这样的开销是可以接受的。总的来说,PackedFunc 是 TVM 的通用“胶水层”,我们在编译和部署模块中都大量依赖它。
组件
由于 TVM 支持多种不同类型的硬件设备,我们也需要支持对应的不同驱动程序。我们必须使用这些驱动 API 来加载内核、以打包形式设置参数并启动内核执行。同时,我们还需要对驱动 API 进行封装,以确保暴露给用户的接口是线程安全的。因此,我们通常会在 C++ 中编写这些驱动层 Glue 代码,并通过 PackedFunc 将其暴露给用户。显然,我们不可能为每类函数都单独编写接口,因此 PackedFunc 再次成为解决方案。
TVM 将编译结果抽象为一个 Module。
用户可以从 Module 中以 PackedFunc 的形式获取已编译函数。生成的代码在运行时可以动态地从 Module 中获取目标函数,并在第一次调用时缓存句柄,后续复用。这使得我们可以在生成代码中链接设备端函数,并调用任意 PackedFunc(例如 Python 回调)。
ModuleNode 是一个抽象类,不同设备类型可以各自实现。例如,我们已支持 CUDA、Metal、OpenCL 以及动态库(Shared Library)。这种抽象设计使得引入新设备变得简单,而无需重新生成每种设备的主机端代码。
远程部署
PackedFunc 和 Module 系统也使得我们可以将函数直接部署到远程设备上。在底层,我们提供了一个 RPCModule,它负责序列化参数、进行数据传输,并在远程设备上启动计算。
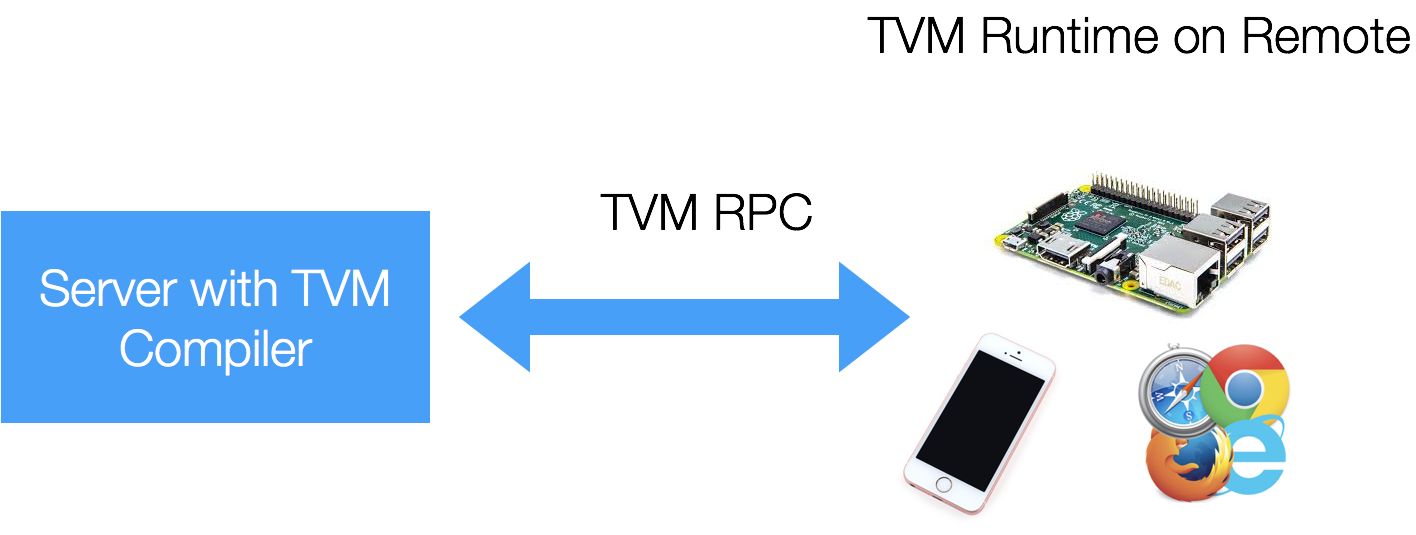
RPC 服务器本身非常精简,可以直接与运行时一起打包。我们可以在 iPhone、Android、树莓派甚至浏览器中启动一个最小化的 TVM RPC 服务器。交叉编译、模块打包与测试都可以在同一个脚本中完成。更多细节可参考 tutorial-cross-compilation-and-rpc。
这种即时反馈带来了显著优势。例如,当我们希望验证生成的代码在 iPhone 上的正确性时,不再需要手动用 Swift/Objective-C 重写测试样例——我们可以直接使用 RPC 在 iPhone 上执行代码,将结果复制回主机,并使用 numpy 进行验证。同样,我们也可以使用同一个脚本进行性能分析。
TVM 对象与编译器栈
如前所述,我们在 PackedFunc 运行时系统之上构建了编译器栈的 API。由于研究需求,编译器 API 经常需要不断变化。当我们想要测试新的语言原语时,就需要引入新的语言对象或 IR 节点。但是我们又不希望频繁修改 API。此外,我们还希望:
-
能够序列化任意语言对象和 IR;
-
能够在前端语言中探索、打印和操作 IR 对象,以便进行快速原型开发。
为了解决这些问题,我们引入了一个基类Object。
编译器栈中的所有语言对象都是 Object 的子类。每个对象都包含一个字符串 type_key,用于唯一标识对象类型。我们选择字符串而不是整数作为类型键的原因是:这样可以以去中心化方式添加新的 Object 类,而无需往中心仓库中添加代码。为了加速调度,我们会在运行时为每个 type_key 分配一个整数 type_index。
由于一个 Object 通常会在语言中被多个地方引用,我们使用 shared_ptr 来管理对象引用。ObjectRef 类用于表示对 Object 的引用,可以将其视为指向Object容器的 shared_ptr。我们也可以定义 ObjectRef 的子类来对应不同的 Object子类型。每个 Object 子类都需要实现 RegisterReflection 函数。
每个Object子类会重写该函数来注册其成员。下面是 IntImmNode 的示例实现:
class IntImmNode : public PrimExprNode {
public:
/*! \brief the Internal value. */
int64_t value;
static void RegisterReflection() {
namespace refl = tvm::ffi::reflection;
refl::ObjectDef<IntImmNode>().def_ro("value", &IntImmNode::value);
}
TVM_FFI_DECLARE_OBJECT_INFO_FINAL("ir.IntImm", IntImmNode, PrimExprNode);
};
// in cc file
TVM_FFI_STATIC_INIT_BLOCK() { IntImmNode::RegisterReflection(); }
RegisterReflection 为我们提供了一个反射接口,用于注册对象的成员。我们可以利用这个函数递归地访问并序列化任何语言对象。同时,它也使我们可以在前端语言中轻松访问对象的字段。例如:
import tvm
x = tvm.tir.IntImm("int32", 1)
# access the value field of IntImmNode
print(x.value)
新的 Object 可以仅在 C++ 中添加而无需修改前端运行时,从而方便扩展编译器栈。需要注意的是,这种机制不是访问成员的最高性能方式,但它是最简单的方法之一。我们发现这种方式非常适合我们的目的:用 Python 进行测试和原型开发,而真正的计算和重工作交由 C++ 完成。
实现细节
PackedFunc 中的每个参数由一个联合体 TVMValue 和一个类型码组成。这样的设计使得动态类型语言可以直接转换到对应类型,而静态类型语言则可以在转换过程中执行运行时类型检查。
相关文件包括:
-
packed_func.h —— C++ API
-
c_runtime_api.cc —— C API 以及如何提供回调支持
为了支持扩展类型,我们使用了一个注册表系统来注册类型相关信息,例如允许 C++ 中对 any的支持。更多详情可参考:Extension
types。
与运行时相关的信息
- Vulkan Runtime