设计与架构
本文档适用于想要了解 TVM 架构或积极开发项目的开发者。本文档组织结构如下:
- 整体编译流程示例:概述 TVM 如何将一个高级模型描述转换为可部署模块的各个步骤。建议首先阅读本节以了解基础流程。
- 简要介绍 TVM 栈中的关键组件。您也可以参考 TensorIR 深度解析 和 Relax 深度解析,了解 TVM 栈中两个核心部分的详细内容。
本指南提供了架构的一些补充视图。首先研究端到端的编译流程,并讨论关键的数据结构和转换。这种基于 runtime 的视图侧重于运行编译器时每个组件的交互,接下来我们将研究代码库的逻辑模块及其关系。本部分将提供该设计的静态总体视图。
编译流程示例
本指南研究编译器中的编译流程示例,下图展示了流程。从高层次来看,它包含以下步骤:
- 导入: 前端组件将模型引入到 IRModule 中,它包含了内部表示模型的函数集合。
- 转换: 编译器将 IRModule 转换为功能与之等效或近似等效(例如在量化的情况下)的 IRModule。许多转换与 target(后端)无关,并且允许 target 配置转换 pipeline。
- Target 转换: 编译器将 IRModule 转换(codegen)为指定 target 的可执行格式。target 的转换结果被封装为 runtime.Module,可以在 runtime 环境中导出、加载和执行。
- Runtime 执行: 用户加载 runtime.Module,并在支持的 runtime 环境中运行编译好的函数。
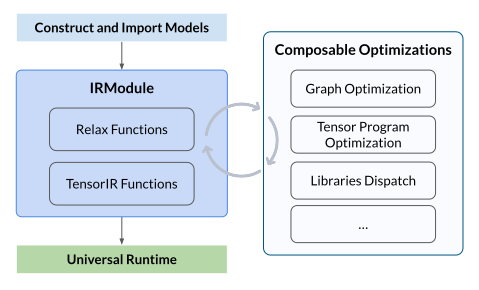
关键数据结构
设计和理解复杂系统的最佳方法之一,就是识别关键数据结构和操作(转换)这些数据结构的 API。识别了关键数据结构后,就可以将系统分解为逻辑组件,这些逻辑组件定义了关键数据结构的集合,或是数据结构之间的转换。
IRModule 是整个堆栈中使用的主要数据结构。一个 IRModule(intermediate representation module)包含一组函数。目前支持两种主要的功能变体(variant):
- relay::Function 是一种高层功能程序表示。一个 relay.Function 通常对应一个端到端的模型。可将 relay.Function 视为额外支持控制流、递归和复杂数据结构的计算图。
- tir::PrimFunc 是一种底层程序表示,包含循环嵌套选择、多维加载/存储、线程和向量/张量指令的元素。通常用于表示算子程序,这个程序在模型中执行一个(可融合的)层。 在编译期间,Relay 函数可降级为多个 tir::PrimFunc 函数和一个调用这些 tir::PrimFunc 函数的顶层函数。
在编译和转换过程中,所有的 Relax 运算符都会被下沉(lower)为 tir::PrimFunc 或 TVM PackedFunc,这些函数可以直接在目标设备上执行。而对 Relax 运算符的调用,则会被下沉为对低层函数的调用(例如 R.call_tir 或 R.call_dps)。
转换
前面介绍了关键数据结构,接下来讲转换。转换的目的有:
- 优化:将程序转换为等效,甚至更优的版本。
- 降级:将程序转换为更接近 target 的较低级别表示。 relay/transform 包含一组优化模型的 pass。优化包括常见的程序优化(例如常量折叠和死码消除),以及特定于张量计算的 pass(例如布局转换和 scale 因子折叠)。
Relax 转换
Relax 转换包括一系列应用于 Relax 函数的 Pass。优化内容包括常见的图级优化(如常量折叠、无用代码消除等),以及后端特定的优化(例如库调度)。
tir 转换
tir 转换包含一组应用于 tir 函数的 pass,主要包括两类:
- TensorIR 调度(TensorIR schedule): TensorIR 调度旨在为特定目标优化 TensorIR 函数,通常由用户指导控制目标代码的生成。对于 CPU 目标,TIR PrimFunc 即使没有调度也可以生成有效代码并在目标设备上运行,但性能较低。对于 GPU 目标,调度是生成有效线程绑定代码的关键。详情请参考 TensorIR 转换教程。此外,TVM 提供了
MetaSchedule来自动搜索最优的 TensorIR 调度。 - 降层 Pass(Lowering Passes): 这些 Pass 通常在应用调度后执行,将 TIR PrimFunc 转换为功能等价但更贴近目标表示的版本。例如,有些 Pass 会将多维访问扁平化为一维指针访问,或者将中间表示中的 intrinsic 扩展为目标特定的形式,并对函数入口进行修饰以符合运行时调用约定。
许多底层优化可以在目标阶段由 LLVM、CUDA C 以及其他目标编译器处理。因此,我们将寄存器分配等底层优化留给下游编译器处理,仅专注于那些它们未涵盖的优化。
跨层转换(Cross-level transformations)
Apache TVM 提供统一的策略来优化端到端模型。由于 IRModule 同时包含 Relax 和 TIR 函数,跨层转换的目标是在这两类函数之间应用变换来修改 IRModule。
例如,relax.LegalizeOps Pass 会通过将 Relax 算子降层为 TIR PrimFunc 并添加至 IRModule 中,同时将原有的 Relax 算子替换为对该 TIR 函数的调用,从而改变 IRModule。另一个例子是 Relax 中的算子融合流程(包括 relax.FuseOps 和 relax.FuseTIR),它将多个连续的张量操作融合为一个操作。与以往手动定义融合规则的方法不同,Relax 的融合流程会分析 TIR 函数的模式,自动检测出最佳融合策略。
目标转换(Target Translation)
目标转换阶段将 IRModule 转换为目标平台的可执行格式。对于 x86 和 ARM 等后端,TVM 使用 LLVM IRBuilder 构建内存中的 LLVM IR。也可以生成源码级别的语言,如 CUDA C 和 OpenCL。此外,TVM 支持通过外部代码生成器将 Relax 函数(子图)直接翻译为目标代码。
目标代码生成阶段应尽可能轻量,大多数转换和降层操作应在此阶段之前完成。
TVM 还提供了 Target 结构体用于指定编译目标。目标信息也可能影响前期转换操作,例如目标的向量长度会影响向量化行为。
Runtime 执行
TVM runtime 的主要目标是提供一个最小的 API,从而能以选择的语言(包括 Python、C++、Rust、Go、Java 和 JavaScript)加载和执行编译好的工件。以下代码片段展示了一个 Python 示例:
import tvm
# Python 中 runtime 执行程序示例,带有类型注释
mod: tvm.runtime.Module = tvm.runtime.load_module("compiled_artifact.so")
arr: tvm.runtime.Tensor = tvm.runtime.tensor([1, 2, 3], device=tvm.cuda(0))
fun: tvm.runtime.PackedFunc = mod["addone"]
fun(arr)
print(arr.numpy())
tvm.runtime.Module 封装了编译的结果。runtime.Module 包含一个 GetFunction 方法,用于按名称获取 PackedFuncs。
tvm.runtime.PackedFunc 是一种为各种构造函数消解类型的函数接口。runtime.PackedFunc 的参数和返回值的类型如下:POD 类型(int, float)、string、runtime.PackedFunc、runtime.Module、runtime.Tensor 和 runtime.Object 的其他子类。
tvm.runtime.Module 和 tvm.runtime.PackedFunc 是模块化 runtime 的强大机制。例如,要在 CUDA 上获取上述 addone 函数,可以用 LLVM 生成主机端代码来计算启动参数(例如线程组的大小),然后用 CUDA 驱动程序 API 支持的 CUDAModule 调用另一个 PackedFunc。OpenCL 内核也有相同的机制。
以上示例只处理了一个简单的 addone 函数。下面的代码片段给出了用相同接口执行端到端模型的示例:
import tvm
# python 中 runtime 执行程序的示例,带有类型注释
factory: tvm.runtime.Module = tvm.runtime.load_module("resnet18.so")
# 在 cuda(0) 上为 resnet18 创建一个有状态的图执行模块
gmod: tvm.runtime.Module = factory["resnet18"](tvm.cuda(0))
data: tvm.runtime.Tensor = get_input_data()
# 设置输入
gmod["set_input"](0, data)
# 执行模型
gmod["run"]()
# 得到输出
result = gmod["get_output"](0).numpy()
主要的结论是 runtime.Module 和 runtime.PackedFunc 可以封装算子级别的程序(例如 addone),以及端到端模型。
总结与讨论
综上所述,编译流程中的关键数据结构有:
- IRModule:包含 relay.Function 和 tir.PrimFunc
- runtime.Module:包含 runtime.PackedFunc
编译基本是在进行关键数据结构之间的转换。
- relay/transform 和 tir/transform 是确定性的基于规则的转换
- meta-schedule 则包含基于搜索的转换
最后,编译流程示例只是 TVM 堆栈的一个典型用例。将这些关键数据结构和转换提供给 Python 和 C++ API。然后,就可以像使用 numpy 一样使用 TVM,只不过关注的数据结构从 numpy.ndarray 改为 tvm.IRModule。以下是一些用例的示例:
- 用 Python API 直接构建 IRModule。
- 编写一组自定义转换(例如自定义量化)。
- 用 TVM 的 Python API 直接操作 IR。
tvm/support
support 模块包含基础架构最常用的程序,例如通用 arena 分配器(arena allocator)、套接字(socket)和日志(logging)。
tvm/runtime
runtime 是 TVM 技术栈的基础。它提供加载和执行已编译产物的机制。运行时定义了一套稳定的 C API 标准接口,用于与前端语言(如 Python 和 Rust)交互。
除了 ffi::Function, runtime::Object 是 TVM 运行时的核心数据结构之一。它是一个带有类型索引的引用计数基类,支持运行时类型检查和向下转型。该对象系统允许开发者向运行时引入新的数据结构,例如 Array、Map 以及新的 IR 数据结构。
除了用于部署场景,TVM 编译器本身也大量依赖运行时机制。所有 IR 数据结构都是 runtime::Object 的子类,因此可以直接从 Python 前端访问和操作。我们使用 PackedFunc 机制将各种 API 暴露给前端使用。
不同硬件后端的运行时支持定义在 runtime 子目录中(例如 runtime/opencl)。这些特定于硬件的运行时模块定义了设备内存分配和设备函数序列化的 API。
runtime/rpc 实现了对 PackedFunc 的 RPC 支持。我们可以利用 RPC 机制将交叉编译后的库发送到远程设备,并基准测试其执行性能。该 RPC 基础设施使得能够从多种硬件后端收集数据,用于基于学习的优化。
tvm/node
node 模块在 runtime::Object 的基础上为 IR 数据结构增加了更多功能。其主要功能包括:反射、序列化、结构等价性检查以及哈希计算。
得益于 node 模块,我们可以在 Python 中通过字段名直接访问 TVM IR 节点的任意字段:
x = tvm.tir.Var("x", "int32")
y = tvm.tir.Add(x, x)
# a 和 b 是 tir.Add 节点的字段
# 可以通过字段名直接访问
assert y.a == x
我们还可以将任意 IR 节点序列化为 JSON 格式,并加载回来。这种保存/加载和查看 IR 节点的能力为提高编译器的可用性打下了基础。
tvm/ir
tvm/ir 文件夹包含所有 IR 函数变体所共享的统一数据结构与接口。该模块中的组件被 tvm/relax 和 tvm/tir 共享,主要包括:
- IRModule
- 类型
- PassContext 和 Pass
- Op
不同的函数变体(如 relax.Function 和 tir.PrimFunc)可以共存于一个 IRModule 中。尽管这些变体的内容表示不同,但它们使用相同的数据结构来表示类型。因此,不同函数变体之间可以共享函数签名的表示结构。统一的类型系统使得在定义好调用约定的前提下,一个函数变体可以调用另一个,从而为跨函数变体的优化奠定了基础。
此外,我们还提供了统一的 PassContext 用于配置 Pass 行为,并提供组合 Pass 的方式构建优化流程。如下示例:
# 配置 tir.UnrollLoop pass 的行为
with tvm.transform.PassContext(config={"tir.UnrollLoop": { "auto_max_step": 10 }}):
# 在该上下文下执行的代码
Op 是用于表示系统内置的原始操作符/内建指令的通用类。开发者可以向系统注册新的 Op,并附加属性(例如该操作是否是逐元素操作)。
tvm/target
target 模块包含将 IRModule 转换为目标运行时代码的所有代码生成器,同时也提供了一个通用的 Target 类用于描述目标平台。
编译流程可以根据目标平台的属性信息和每个目标 id(如 cuda、opencl)所注册的内建信息来自定义。
tvm/relax
Relax 是用于表示模型计算图的高级 IR。多种优化过程定义在 relax.transform 中。需要注意的是,Relax 通常与 TensorIR 的 IRModule 协同工作,许多转换会同时作用于 Relax 和 TensorIR 函数。更多信息可参考: Relax 深度解析。
tvm/tir
TIR 定义了低级程序表示。我们使用 tir::PrimFunc 来表示可以由 TIR Pass 转换的函数。除了 IR 数据结构,TIR 模块还包括:
- 位于
tir/schedule中的一组调度原语 - 位于
tir/tensor_intrin中的内置指令 - 位于
tir/analysis中的分析 Pass - 位于
tir/transform中的转换/优化 Pass
更多信息请参考: TensorIR 深度解析。
tvm/arith
该模块与 TIR 紧密相关。低级代码生成中的一个核心问题是对索引的算术属性进行分析——如是否为正数、变量界限、描述迭代器空间的整数集合等。arith 模块提供了一套主要用于整数分析的工具,TIR Pass 可以利用这些工具简化和优化代码。
tvm/te 和 tvm/topi
TE(Tensor Expression)是用于描述张量计算的领域专用语言(DSL)。需要注意的是,Tensor Expression 本身并不是可以直接存储进 IRModule 的自包含函数。我们可以使用 te.create_prim_func 将其转换为 tir::PrimFunc,然后集成进 IRModule。
尽管可以使用 TIR 或 TE 为每个场景直接构造算子,但这种方式较为繁琐。为此,topi(Tensor Operator Inventory)提供了一组预定义算子,覆盖了 numpy 操作和深度学习常见操作。
tvm/meta_schedule
MetaSchedule 是一个用于自动搜索优化程序调度的系统。它是 AutoTVM 和 AutoScheduler 的替代方案,可用于优化 TensorIR 调度。需要注意的是,MetaSchedule 目前仅支持静态形状工作负载。
tvm/dlight
DLight 提供一套预定义、易用且高性能的 TIR 调度策略。其目标包括:
- 全面支持动态形状工作负载
- 轻量级:提供无需调优或仅需极少调优的调度策略,且性能合理
- 稳定性强:DLight 的调度策略具有通用性,即使当前规则不适用也不会报错,而是自动切换至下一个规则