Relay IR 简介
本文介绍 Relay IR——第二代 NNVM。学习本节内容,需要具备一定的编程背景,以及熟悉计算图表示的深度学习框架。
学习本节内容,你将了解:
- 支持传统的数据流式编程和转换。
- 支持函数式作用域、let-binding,并使其成为功能齐全的可微分语言。
- 允许用户混合两种编程风格。
使用 Relay 构建计算图
传统的深度学习框架使用计算图作为中间表示(IR)。计算图(或数据流图)是表示计算的有向无环图(DAG)。尽管数据流图由于缺乏控制流,而受限于能表达的计算,但其易用性极大简化了实现自动微分和编译异构执行环境(例如,在专用硬件上执行部分图)。

您可以使用 Relay 构建计算(数据流)图。具体来说,上面的代码展示了如何构造一个简单的两节点图。您会发现该示例的语法与现有的计算图 IR(如 NNVMv1)没有太大区别,唯一的区别在于术语:
- 现有框架通常使用计算图和子图
- Relay 使用函数,例如–
fn (%x),表示计算图
每个数据流节点(dataflow node)都是 Relay 中的一个 CallNode。Relay Python DSL 允许快速构建数据流图(dataflow graph)。以上代码强调显式地构造了一个 Add 节点,其两个输入点都指向 %1。深度学习框架评估上述程序时,会按照拓扑顺序计算节点,%1 只会计算一次。
尽管这种现象对于深度学习框架的构建者来说很常见,但对于 PL 研究人员来说可能并非如此。如果实现一个简单的 visitor 来打印结果,并将结果视为嵌套调用表达式,它会变成 log(%x) + log(%x)。
当 DAG 中存在共享节点时,这种歧义是由对程序语义的不同解释引起的。在正常的函数式编程 IR 中,嵌套表达式被视为表达式树,其没有考虑到 %1 实际上在 %2 中重复使用了两次这一事实。
Relay IR 关注了这种差异。通常,深度学习框架用户以这种方式构建计算图,经常发生 DAG 节点重用。因此,当以文本格式打印出 Relay 程序时,每行打印一个 CallNode,并为每个 CallNode 分配一个临时 id (%1, %2),以便在程序的后面部分可以引用每个公共节点。
模块:支持多个函数(计算图)
到目前为止,已经介绍了如何将数据流图构建为函数。有人自然会问:我们能不能支持多种功能,让它们互相调用?Relay 允许将多个函数组合在一个模块中;下面的代码展示了一个函数调用另一个函数的示例。
def @muladd(%x, %y, %z) {
%1 = mul(%x, %y)
%2 = add(%1, %z)
%2
}
def @myfunc(%x) {
%1 = @muladd(%x, 1, 2)
%2 = @muladd(%1, 2, 3)
%2
}
模块可以看作是一个 Map<GlobalVar, Function>。这里 GlobalVar 只是一个 id,用于表示模块中的函数。 @muladd 和 @myfunc 在上面的例子中是 GlobalVars。
当一个 CallNode 用于调用另一个函数时,对应的 GlobalVar 存储在 CallNode 的 op 字段中。它包含一个间接级别——要使用相应的 GlobalVar 从模块中查找被调用函数的主体。
在这种特殊情况下,也可以直接将 Function 的引用作为 op 存储在 CallNode 中。那么,为什么要引入 GlobalVar 呢?主要原因是 GlobalVar 将定义/声明解耦,并启用函数的递归和延迟声明。
def @myfunc(%x) {
%1 = equal(%x, 1)
if (%1) {
%x
} else {
%2 = sub(%x, 1)
%3 = @myfunc(%2)
%4 = add(%3, %3)
%4
}
}
以上示例 @myfunc 递归调用自身。使用 GlobalVar @myfunc 来表示函数,避免了数据结构中的循环依赖。至此,已经介绍了 Relay 中的基本概念。注意,Relay 比 NNVMv1 有以下改进:
- 简洁的文本格式,简化了编写过程的调试。
- 联合模块中对子图函数的最好的支持,使得联合优化的可能性更大,例如内联和调用约定规范。
- 原生的前端语言互用性,例如,所有数据结构都可以在 Python 中访问,这使得用户可以在 Python 中快速构建优化原型,并将其与 C++ 代码混合。
let 绑定和范围
到目前为止,已经介绍了如何用深度学习框架中旧的方式来构建计算图。本节将讨论 Relay 引入的一个新的重要结构——let 绑定。
所有高级编程语言都使用 let 绑定。在 Relay 中,它是一个具有三个字段 Let(var, value, body) 的数据结构。评估 let 表达式时,首先评估 value 部分,将其分配给 var,然后在 body 表达式中返回评估结果。
可以使用一系列 let 绑定,来构造与数据流程序逻辑等效的程序。以下代码示例并排显示了一个具有两个表单的程序。
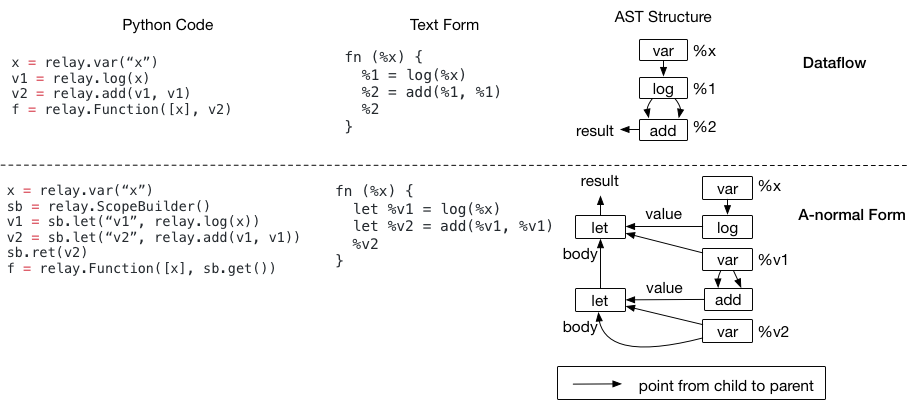
嵌套的 let 绑定称为 A 范式,通常用作函数式编程语言中的 IR。仔细看看 AST 结构。虽然这两个程序在语义上是相同的(它们的文本表示也是相同的,除了 A-normal 形式有 let 前缀),但 AST 结构是不同的。
由于程序优化采用这些 AST 数据结构,并对其进行转换,因此这两种不同的结构会影响将要编写的编译器代码。例如,若要检测一个模式 add(log(x), y):
- 在数据流形式中,可以先访问 add 节点,然后直接看它的第一个参数是不是日志。
- 在 A 范式中,不能再直接进行检查,因为要添加的第一个输入是
%v1——保留一个从变量到其绑定值的映射,并查找该映射,以便知道% v1是一个日志。
不同的数据结构会影响编写转换的方式,请牢记这一点。所以,作为一个深度学习框架的开发者,你可能会问,为什么我们需要 let 绑定?你的 PL 朋友总是会告诉你 let 很重要——因为 PL 是一个相当成熟的领域,其背后一定有一些智慧。
为什么需要 let 绑定
let 绑定的一个关键用法是它指定了计算范围。下面的例子没有使用 let 绑定:

当试图决定应该在哪里评估节点 %1 时,问题就来了。尤其是,尽管文本格式建议在 if 范围之外评估节点 %1,但 AST(如图所示)并不建议这样做。实际上,数据流图从未定义其评估范围。这在语义上引入了一些歧义。
当有闭包时,这种歧义变得更加有趣。下面的程序返回一个闭包。我们不确定在哪里计算 %1;它可以在闭包的内部,也可以在闭包外部。
fn (%x) {
%1 = log(%x)
%2 = fn(%y) {
add(%y, %1)
}
%2
}
let 绑定解决了这个问题,因为值的计算发生在 let 节点。在这两个程序中,如果将 %1 = log(%x) 改为 let %v1 = log(%x),就可以清楚地指定计算位置在 if 范围和闭包之外。可见 let-binding 给出的计算站点的规范更精确,并且在生成后端代码时很有用(跟 IR 中的规范类似)。
另一方面,不指定计算范围的数据流形式确实有其自身的优势——即我们在生成代码时无需担心将 let 放在哪里。数据流形式还为后面的传递提供了更多自由来决定将评估点放在哪里。因此,当您发现方便时,在优化的初始阶段使用程序的数据流形式可能不是一个坏主意。如今,Relay 中的许多优化都是为了优化数据流程序而编写的。
但是,当将 IR 降级到实际的 runtime 程序时,需要精确计算范围。特别是,使用子函数和闭包时,我们希望明确指定计算范围。在后期执行特定优化中 let-binding 可用于解决此问题。
IR 转换的影响
希望你现在已经熟悉这两种表示形式。大多数函数式编程语言以 A 范式进行分析,其中分析器不需要注意表达式是否为 DAG。
Relay 同时支持数据流形式和 let 绑定。让框架开发者选择他们熟悉的表示很重要。然而,这确实对于编写 pass 有一些影响:
- 如果你具备数据流相关知识,且要处理 let,将 var 映射到表达式,以便在遇到 var 时查找。因为任何情况下都需要一个从表达式到转换表达式的映射,所以这可能意味着最少的变更。注意,这将有效地删除程序中的所有 let。
- 如果你具备 PL 相关知识,且熟悉 A 范式,我们将为 A 范式 pass 提供数据流。
- 对于 PL 开发者而言,在实现某些东西(比如数据流到 ANF 的转换)时,表达式可以是 DAG,这通常意味着应该使用
Map<Expr, Result>访问表达式,并且转换后的表达式结果只计算一次,因此结果表达式保持通用结构(common structure)。
本节内容未涵盖的高阶概念,如符号 shape 推断、多态函数,欢迎查看其他材料。